salesforce/CodeT5
Salesforce's code models that actually read your variable names
Research-grade code LLMs built on T5, with a specific bet that understanding identifiers matters for generation quality.
Not currently ranked — collecting fresh signals.
star history
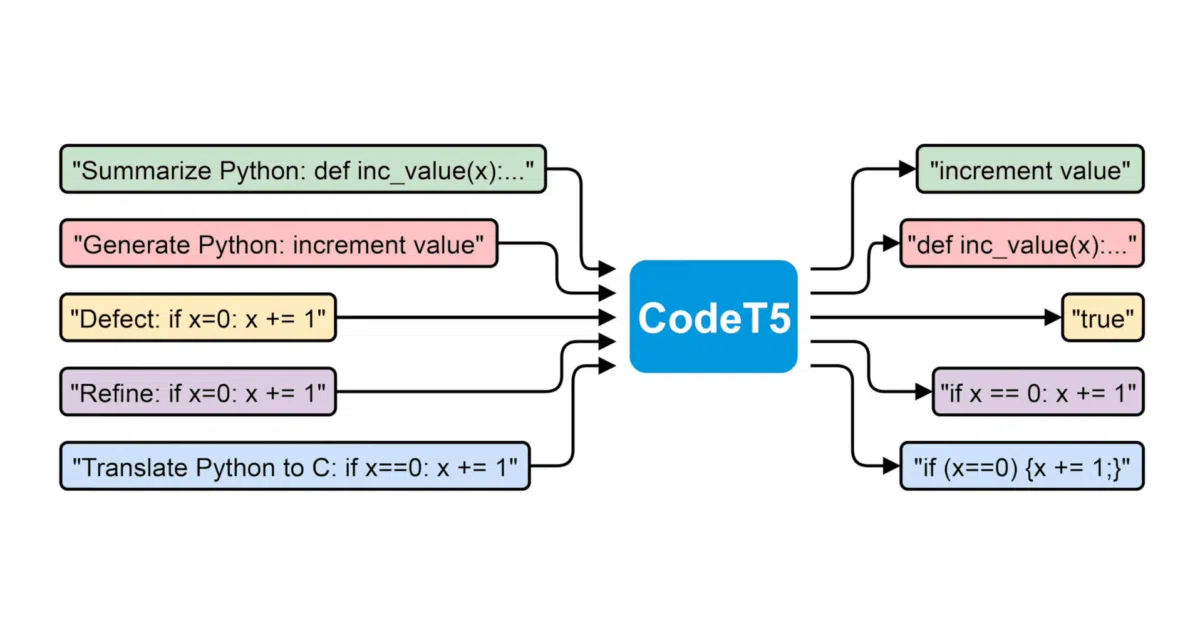
What it does CodeT5 and CodeT5+ are encoder-decoder language models fine-tuned for software tasks: generating code from descriptions, completing partial functions, and summarizing code back to English. Salesforce Research released them as open models with HuggingFace checkpoints and a VS Code plugin demo.
The interesting bit The original CodeT5 (EMNLP 2021) made “identifier-aware” pre-training its signature move — treating variable and function names as meaningful tokens rather than opaque strings. CodeT5+ (2023) scales this up with larger checkpoints and reinforcement learning via the related CodeRL work. It’s a research lineage, not a product.
Key highlights
- Three concrete capabilities: text-to-code, function autocompletion, code summarization
- Pre-trained checkpoints on HuggingFace: base, large, and large-ntp-py variants
- Fine-tuned models available for downstream tasks and multilingual summarization
- BSD-3 license with an unusual ethical-use rider (no violence, environmental destruction, etc.)
- VS Code plugin demo shows real integration, though it’s labeled a research release
Caveats
- README is mostly paper links and release notes; setup instructions and benchmarks are absent
- The VS Code plugin appears to be a demo, not a maintained extension
- CodeT5+ is still an arXiv preprint as of the README’s last update
Verdict Worth exploring if you’re doing research on code LLMs or need a T5-based baseline to compare against newer decoder-only models. Skip if you want a batteries-included coding assistant — this is the raw model weights and papers.
Frequently asked
- What is salesforce/CodeT5?
- Research-grade code LLMs built on T5, with a specific bet that understanding identifiers matters for generation quality.
- Is CodeT5 open source?
- Yes — salesforce/CodeT5 is open source, released under the BSD-3-Clause license.
- What language is CodeT5 written in?
- salesforce/CodeT5 is primarily written in Python.
- How popular is CodeT5?
- salesforce/CodeT5 has 3.1k stars on GitHub.
- Where can I find CodeT5?
- salesforce/CodeT5 is on GitHub at https://github.com/salesforce/CodeT5.