punica-ai/punica
One backbone, many LoRA tenants
Punica turns one GPU into a multi-tenant LoRA host by sharing the base model and encapsulating adapter math in a custom CUDA kernel.
Not currently ranked — collecting fresh signals.
star history
What it does Punica is a serving engine for multiple LoRA-finetuned large language models that share the same pretrained backbone. Instead of loading a separate full model for each finetune, it keeps one copy of the base weights in memory and applies the small LoRA matrices—adding roughly 1% overhead per adapter—on the fly. A single forward pass can mix requests targeting entirely different adapters.
The interesting bit
The trick is the right-hand side of the LoRA equation. While the shared backbone X@W batches naturally across requests, the adapter terms (x1@A1@B1, ..., xn@An@Bn) do not. Punica rolls these scattered small matrix multiplications into a single CUDA kernel it calls SGMV—Segmented Gather Matrix-Vector multiplication—so the overhead of mixing many adapters in one batch stays minimal.
Key highlights
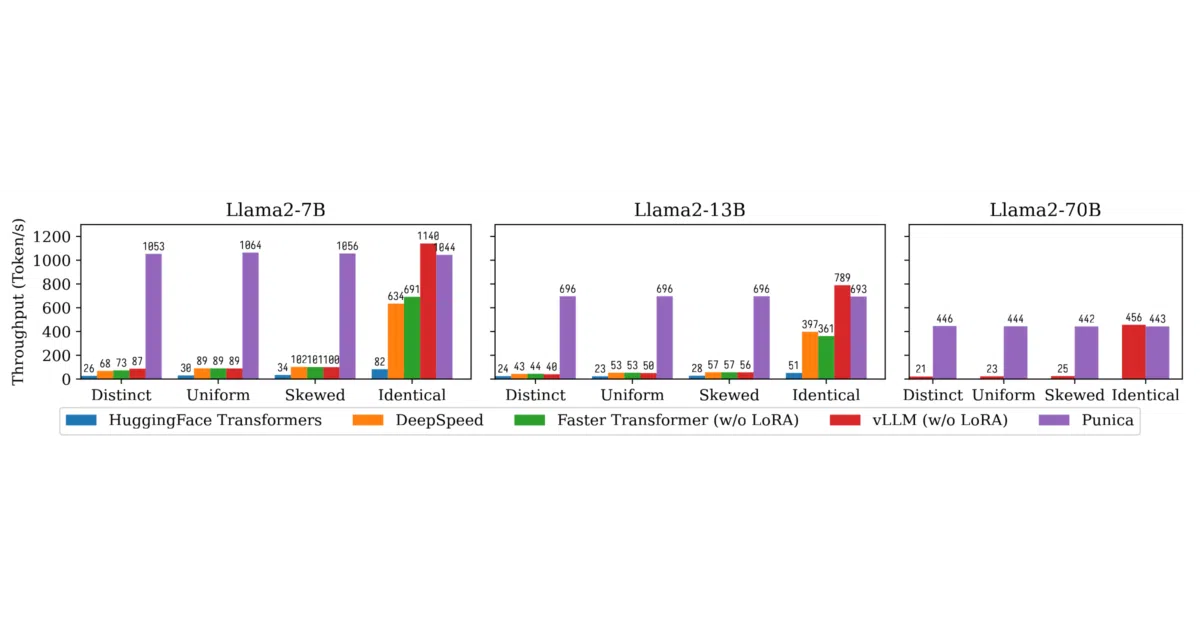
- Claims 12x throughput over HuggingFace Transformers, DeepSpeed, FasterTransformer, and vLLM when serving heterogeneous LoRA requests.
- Handles mixed popularity: works when every request hits a distinct adapter, when they all hit the same one, or anything in between.
- Adds roughly 1% storage and memory overhead per LoRA adapter compared to the base model.
- Ships with a TUI demo for interacting with multiple LoRA models simultaneously.
- Prebuilt wheels available for CUDA 11.8/12.1 and Python 3.10/3.11; source build is the fallback.
Caveats
- Prebuilt binaries are narrow: they target specific CUDA versions (11.8 or 12.1), Python releases (3.10, 3.11), and GPU architectures (8.0, 8.6, 8.9+PTX). Everyone else compiles from source.
- The README does not spell out which base model families or LoRA ranks are supported, so check the code or paper before committing.
Verdict Worth a look if you run a GPU cluster serving many specialized LoRA variants of the same base model. Skip it if you only ever serve one model at a time; vanilla vLLM or similar is likely simpler.
Frequently asked
- What is punica-ai/punica?
- Punica turns one GPU into a multi-tenant LoRA host by sharing the base model and encapsulating adapter math in a custom CUDA kernel.
- Is punica open source?
- Yes — punica-ai/punica is open source, released under the Apache-2.0 license.
- What language is punica written in?
- punica-ai/punica is primarily written in Python.
- How popular is punica?
- punica-ai/punica has 1.2k stars on GitHub.
- Where can I find punica?
- punica-ai/punica is on GitHub at https://github.com/punica-ai/punica.