princeton-nlp/LLM-Shearing
Prune first, train later: shrinking LLaMA on a budget
Because training small language models from scratch is expensive, this codebase shears existing LLaMA checkpoints into smaller variants and continues pre-training them at a fraction of the usual cost.
Not currently ranked — collecting fresh signals.
star history
What it does
This repository implements structured pruning for large language models, taking existing checkpoints like LLaMA-2-7B and compressing them into smaller architectures such as 1.3B and 2.7B parameters. The pruning logic and dynamic batch loading are implemented entirely as callbacks on top of MosaicML’s Composer trainer, leaving the underlying training loop untouched. After a brief pruning phase, the compacted model undergoes continued pre-training to recover accuracy.
The interesting bit
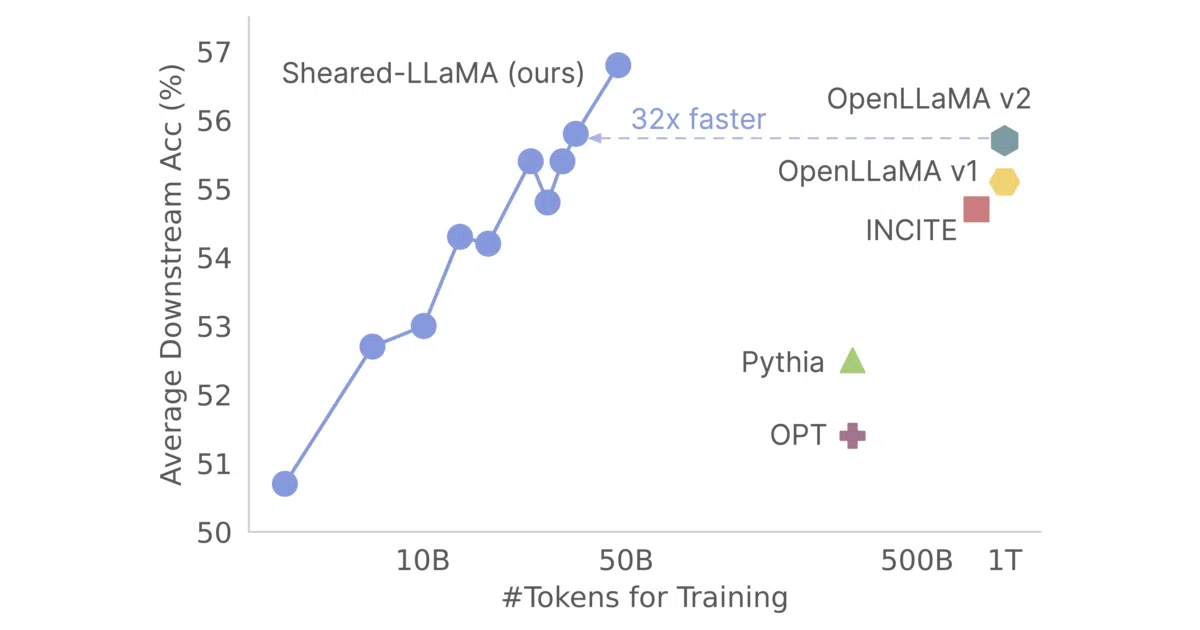
The project treats pruning as a warm-up for further training rather than a terminal compression step: it runs a masking objective for roughly 3,200 steps, physically removes near-zero substructures, and resumes standard pre-training on the slimmed architecture. The authors claim this approach can match OpenLLaMA’s performance at roughly 3% of the pre-training cost, at least for the specific comparison illustrated in their teaser figure.
Key highlights
- Pruning and dynamic data loading live as
Composercallbacks, not trainer patches - Released checkpoints include 1.3B and 2.7B sheared models, pruned-only variants, and instruction-tuned versions
- Includes weight-conversion utilities between Hugging Face and Composer formats
- Explicitly targets
LLaMAandLLaMA-2architectures, with the authors notingMistral-7Bshould be straightforward to adapt
Caveats
Flash Attention 2is not currently supported and may require manual model file edits- Conversion and equivalence-testing utilities are built specifically for
LLaMA/LLaMA-2; other architectures need adaptation - The workflow is tightly coupled to the MosaicML
Composerecosystem, so expect weight-format conversions if your stack lives elsewhere
Verdict
A practical option if you want a capable small model and prefer to carve it from a larger checkpoint than train from scratch. Less appealing if your infrastructure does not already orbit MosaicML’s tooling or if you need immediate Flash Attention 2 support.
Frequently asked
- What is princeton-nlp/LLM-Shearing?
- Because training small language models from scratch is expensive, this codebase shears existing LLaMA checkpoints into smaller variants and continues pre-training them at a fraction of the usual cost.
- Is LLM-Shearing open source?
- Yes — princeton-nlp/LLM-Shearing is open source, released under the MIT license.
- What language is LLM-Shearing written in?
- princeton-nlp/LLM-Shearing is primarily written in Python.
- How popular is LLM-Shearing?
- princeton-nlp/LLM-Shearing has 642 stars on GitHub.
- Where can I find LLM-Shearing?
- princeton-nlp/LLM-Shearing is on GitHub at https://github.com/princeton-nlp/LLM-Shearing.