philferriere/tfoptflow
PWC-Net in pure TensorFlow, no CUDA kernels required
A portable, trainable implementation of a top-tier optical flow network that runs on Windows and multi-GPU setups alike.
Not currently ranked — collecting fresh signals.
star history
What it does
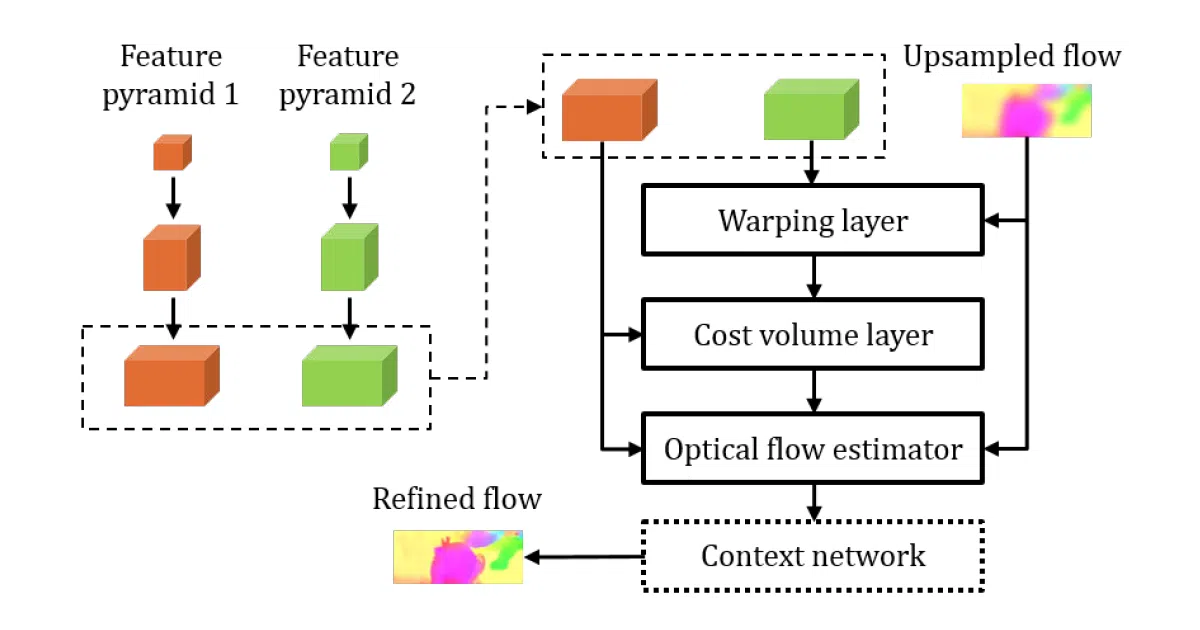
Implements PWC-Net, a 2018 CVPR paper for dense optical flow estimation — predicting pixel-by-pixel motion between two video frames. The repo provides both training and inference in TensorFlow, packaged as Jupyter notebooks with pre-trained models available for download.
The interesting bit
Most prior TensorFlow implementations of this paper were Linux-only inference demos with outdated architectures. This one skips custom CUDA kernels entirely, trading peak speed for portability: it runs on Windows, Linux, even CPU-only machines, and supports multi-GPU training and mixed-precision training. The author also reports beating the paper’s official numbers on the MPI-Sintel ‘final’ benchmark with a different training mix and augmentation strategy.
Key highlights
- Pure TensorFlow ops — no dynamically loaded CUDA kernels
- Trains and infers; multi-GPU and mixed-precision supported
- Pre-trained “small” (4.7M params) and “large” (14.1M params) models available
- Achieves 3.70 EPE on Sintel final vs. 4.39 in the original paper (different training regime)
- ~68ms inference on GTX 1080 Ti for large model, ~54ms for small (unoptimized graphs)
Caveats
- Inference timings are explicitly labeled “rather meaningless” for production since graphs aren’t frozen or optimized (no XLA/TensorRT)
- Training uses a custom downsampled “FlyingThings3DHalfRes” dataset and different augmentations than the official recipe, so the improved numbers aren’t strictly apples-to-apples
- Small, fast-moving objects remain a known failure mode of the underlying algorithm
Verdict
Worth a look if you need to train or fine-tune PWC-Net on non-Linux hardware or want a readable, hackable notebook-based baseline. Skip if you need production-ready speed — the author basically tells you to go freeze and optimize the graph yourself.
Frequently asked
- What is philferriere/tfoptflow?
- A portable, trainable implementation of a top-tier optical flow network that runs on Windows and multi-GPU setups alike.
- Is tfoptflow open source?
- Yes — philferriere/tfoptflow is open source, released under the MIT license.
- What language is tfoptflow written in?
- philferriere/tfoptflow is primarily written in Jupyter Notebook.
- How popular is tfoptflow?
- philferriere/tfoptflow has 530 stars on GitHub.
- Where can I find tfoptflow?
- philferriere/tfoptflow is on GitHub at https://github.com/philferriere/tfoptflow.