pathak22/noreward-rl
Teaching agents to explore out of boredom, not bribery
An ICML 2017 implementation that replaces sparse environment rewards with intrinsic curiosity so agents learn by predicting what happens next.
Not currently ranked — collecting fresh signals.
star history
What it does This is the TensorFlow reference implementation for “Curiosity-driven Exploration by Self-supervised Prediction.” It trains reinforcement learning agents using an Intrinsic Curiosity Module (ICM) that provides motivation when external rewards are sparse or entirely absent. The agent explores by trying to predict the consequences of its own actions, then learning from its prediction errors.
The interesting bit The ICM formulation sidesteps a classic RL trap: agents that get bored once they’ve memorized a level. By rewarding prediction error in a learned feature space rather than raw pixels, the system stays curious about controllable aspects of the world without getting derailed by noise like flickering screens.
Key highlights
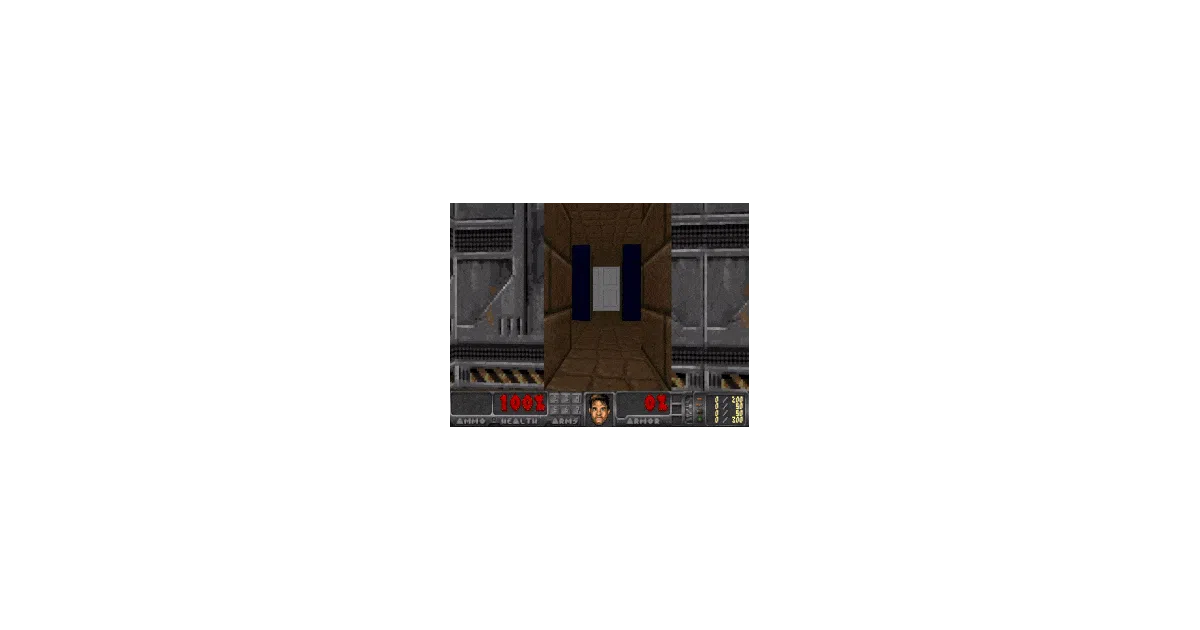
- Trains on Doom (VizDoom) and Super Mario Bros via OpenAI Gym wrappers
- Includes pre-trained model checkpoints for both environments
- Supports full no-reward mode (
--noReward) where the agent learns purely from curiosity - Built on A3C, extending the OpenAI universe-starter-agent codebase
- Self-supervised: no hand-designed exploration bonuses or reward shaping required
Caveats
- Setup is heavy: requires
fceux,xvfb,golang,libboost-all-dev, and other system dependencies - The README notes you “might not need many of these,” which suggests some dependency cruft
- Training hyperparameters differ between environments and require editing
constants.pyby hand
Verdict Worth a look if you’re studying exploration in RL or reproducing classic deep RL baselines. Skip it if you want a clean, modern PyTorch implementation—this is 2017 TensorFlow with 2017 installation friction.
Frequently asked
- What is pathak22/noreward-rl?
- An ICML 2017 implementation that replaces sparse environment rewards with intrinsic curiosity so agents learn by predicting what happens next.
- Is noreward-rl open source?
- Yes — pathak22/noreward-rl is an open-source project tracked on heatdrop.
- What language is noreward-rl written in?
- pathak22/noreward-rl is primarily written in Python.
- How popular is noreward-rl?
- pathak22/noreward-rl has 1.5k stars on GitHub.
- Where can I find noreward-rl?
- pathak22/noreward-rl is on GitHub at https://github.com/pathak22/noreward-rl.