om-ai-lab/VLM-R1
Reinforcement learning beats fine-tuning for vision-language tasks
A training framework that applies DeepSeek-R1's GRPO recipe to multimodal models, with evidence that RL generalizes better than supervised fine-tuning.
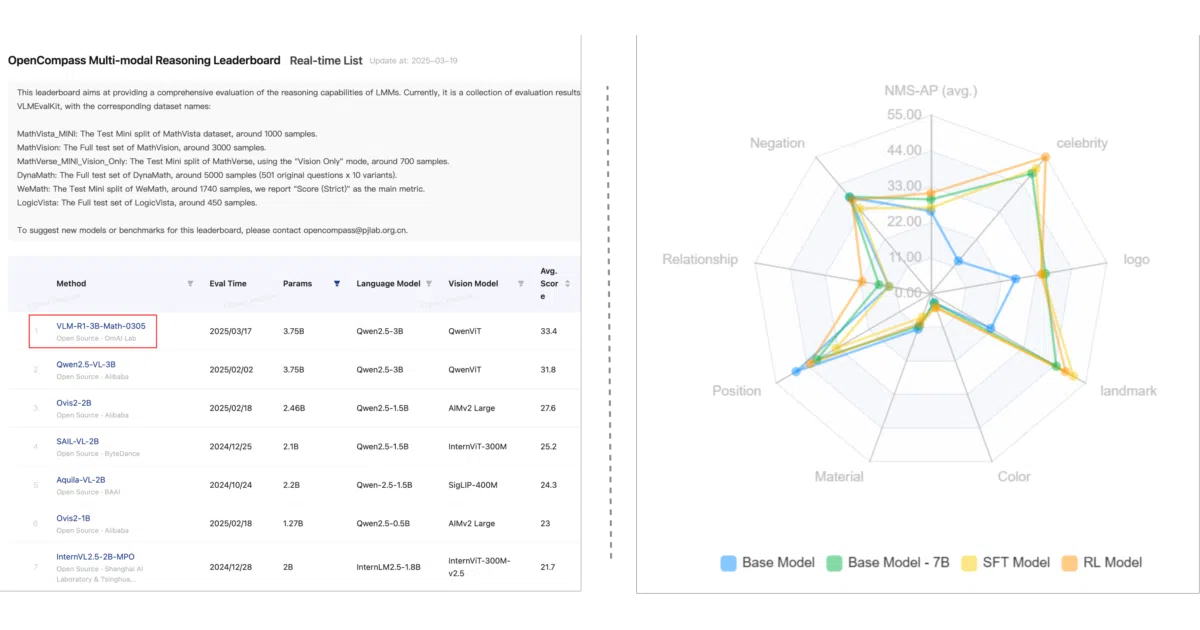
Not currently ranked — collecting fresh signals.
star history
What it does
VLM-R1 is a training framework that applies group relative policy optimization (GRPO) — the reinforcement-learning algorithm behind DeepSeek-R1 — to vision-language models. It fine-tunes Qwen2.5-VL and InternVL on tasks like referring expression comprehension, open-vocabulary detection, multimodal math, and GUI defect detection. The repo provides scripts for full fine-tuning, LoRA, multi-node training, and multi-image input.
The interesting bit
The project’s own comparison shows that after 100–600 training steps, supervised fine-tuning barely improves in-domain performance and actually degrades on out-of-domain data, while the RL-trained model steadily improves and generalizes. They also had to re-run previous SFT experiments after discovering a mismatched pixel configuration — a reminder that baseline comparisons are harder than they look.
Key highlights
- Supports full fine-tuning, frozen vision modules, and LoRA for GRPO training
- Multi-node and multi-image input training ready via shell scripts
- Released checkpoints for REC, OVD, math, and GUI tasks; OVD and math models claim leaderboard positions
- Adapted for Huawei Ascend hardware (Atlas 800T A2, 300I Duo) using vllm-ascend and xllm
- Custom reward functions can be defined per VLM module via
is_reward_customized_from_vlm_module
Caveats
- README is heavy on emoji and leaderboard claims, light on architectural detail
- Setup requires manual dataset downloads and path editing in shell scripts
- SFT comparisons needed a rerun due to a config error; whether this affects other reported results is unclear
Verdict
Worth a look if you’re trying to reproduce R1-style reasoning in multimodal settings and care more about out-of-domain generalization than in-domain accuracy. Skip if you want a polished, one-command training pipeline.
Frequently asked
- What is om-ai-lab/VLM-R1?
- A training framework that applies DeepSeek-R1's GRPO recipe to multimodal models, with evidence that RL generalizes better than supervised fine-tuning.
- Is VLM-R1 open source?
- Yes — om-ai-lab/VLM-R1 is open source, released under the Apache-2.0 license.
- What language is VLM-R1 written in?
- om-ai-lab/VLM-R1 is primarily written in Python.
- How popular is VLM-R1?
- om-ai-lab/VLM-R1 has 6k stars on GitHub.
- Where can I find VLM-R1?
- om-ai-lab/VLM-R1 is on GitHub at https://github.com/om-ai-lab/VLM-R1.