nuclia/nucliadb
A database that actually gets unstructured data
NucliaDB stores and searches text, files, vectors, and annotations with hybrid search built for RAG pipelines.
Not currently ranked — collecting fresh signals.
star history
What it does
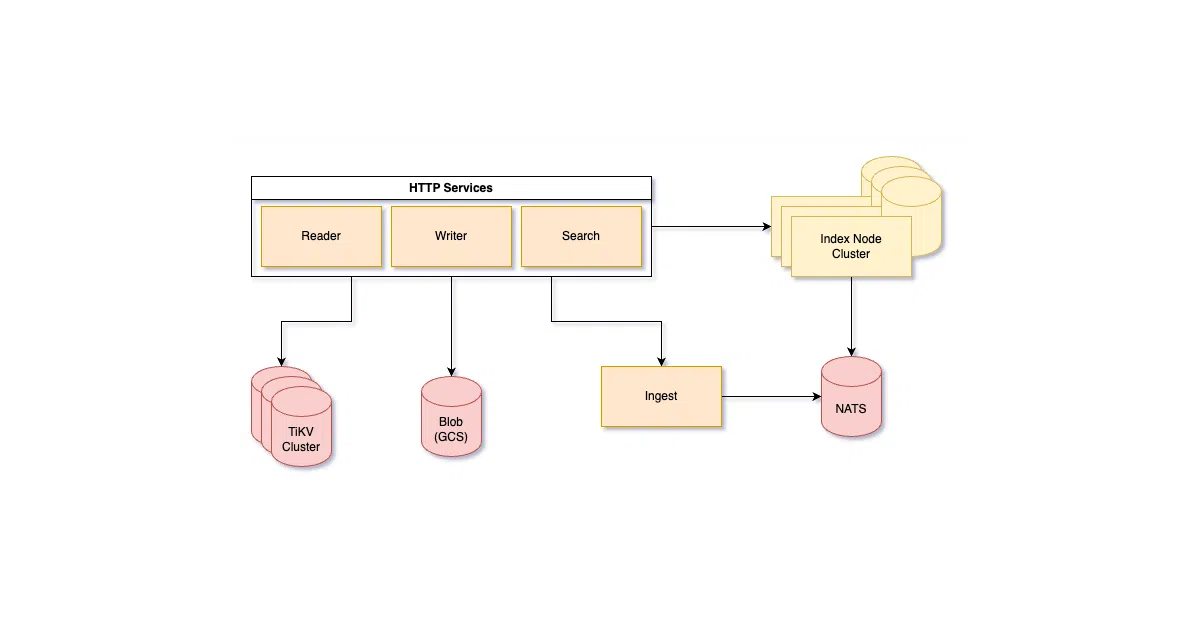
NucliaDB is an open-source database for storing and searching unstructured data. It combines vector search, full-text search, and graph indexes in one system, with a storage layer backed by PostgreSQL and blob support for S3, GCS, and Azure. It’s written in Rust and Python, designed for multi-tenant deployments and large datasets.
The interesting bit
The project is explicitly built around a commercial ecosystem: Nuclia’s cloud “Understanding API” handles the messy work of data extraction and AI enrichment, while NucliaDB serves as the queryable storage layer. The AGPLv3 license means you can use it freely, but modify it and you must publish changes — a deliberate fence around the hosted service business model.
Key highlights
- Hybrid search: vector, keyword, and graph indexes in one query layer
- Field types cover text, files, links, and conversations with paragraph-level indexing
- Exports to HuggingFace datasets and PyTorch-compatible formats
- Distributed search with index replication and cloud-native deployment options
- Role-based security with upstream proxy authentication
Caveats
- The README has rough edges: typos (“multi-teanant”), awkward phrasing (“utilizing the power”), and some feature claims are vague (“Cloud data and insight extraction” lacks detail)
- The cloud API integration is clearly the revenue path; self-hosted users get the database engine without the automatic NLP enrichment
Verdict
Worth evaluating if you’re building RAG infrastructure and want a unified search backend rather than gluing vector and text databases together. Skip it if you need a mature, standalone vector database without the surrounding Nuclia cloud ecosystem.
Frequently asked
- What is nuclia/nucliadb?
- NucliaDB stores and searches text, files, vectors, and annotations with hybrid search built for RAG pipelines.
- Is nucliadb open source?
- Yes — nuclia/nucliadb is an open-source project tracked on heatdrop.
- What language is nucliadb written in?
- nuclia/nucliadb is primarily written in Python.
- How popular is nucliadb?
- nuclia/nucliadb has 718 stars on GitHub.
- Where can I find nucliadb?
- nuclia/nucliadb is on GitHub at https://github.com/nuclia/nucliadb.