naver/splade
BERT learns to fake being a search engine
SPLADE trains sparse neural retrieval that runs on inverted indexes instead of brute-force vector similarity.
Not currently ranked — collecting fresh signals.
star history
What it does
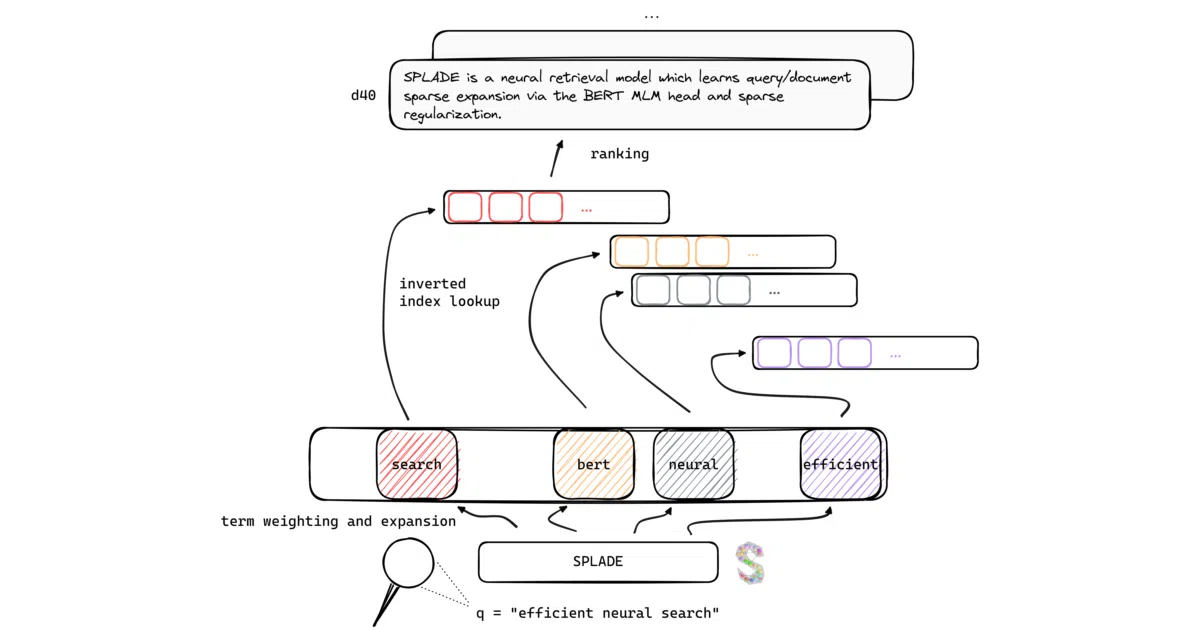
SPLADE is a neural search model that uses BERT’s masked-language-modeling head to expand queries and documents into sparse bag-of-words representations. These sparse vectors plug straight into traditional inverted indexes, giving you lexical matching with learned expansion rather than dense embedding brute force. The repo contains training, indexing, retrieval, and BEIR benchmark evaluation code.
The interesting bit
The trick is sparse regularization: the model learns to be selectively verbose, expanding “neural” to “deep learning” or “artificial neural network” only when useful, while keeping most weights at zero. This lets it generalize better out-of-domain than dense retrievers on BEIR, yet still use the same Lucene-style infrastructure your ops team already runs.
Key highlights
- Six pretrained model variants on Hugging Face, from vanilla v2 (34.0 MRR@10) to efficient SPLADE (38.8 MRR@10)
- Full pipeline:
train.py,index.py,retrieve.py, orall.pyto run everything - Hydra configs for distillation flavors: simple triplets, MarginMSE, self-distillation, ensemble distillation
- Numba-based inverted index or Anserini integration; also PISA for efficient variants
- Mono-GPU config exists (37.2 MRR@10 on 16GB), though default configs assume 4× V100 32GB
Caveats
- Default training configs assume 4 GPUs; single-GPU users must tune batch size and regularization lambdas manually
- “SPLADE is more a class of models rather than a model per se” — regularization strength changes behavior significantly, so picking weights is part of the design choice
Verdict
Worth a look if you’re hitting scaling walls with dense retrieval or need out-of-domain robustness without abandoning inverted-index infrastructure. Skip if you’re committed to pure vector search and don’t care about lexical interpretability.
Frequently asked
- What is naver/splade?
- SPLADE trains sparse neural retrieval that runs on inverted indexes instead of brute-force vector similarity.
- Is splade open source?
- Yes — naver/splade is an open-source project tracked on heatdrop.
- What language is splade written in?
- naver/splade is primarily written in Python.
- How popular is splade?
- naver/splade has 999 stars on GitHub.
- Where can I find splade?
- naver/splade is on GitHub at https://github.com/naver/splade.