nashsu/llm_wiki
Your own Wikipedia, ghostwritten by an LLM from your document pile
It turns your document pile into a persistent, interlinked wiki so the LLM doesn't have to re-read everything every time you ask a question.
Velocity · 7d
+69
★ / day
Trend
↘cooling
star history
What it does
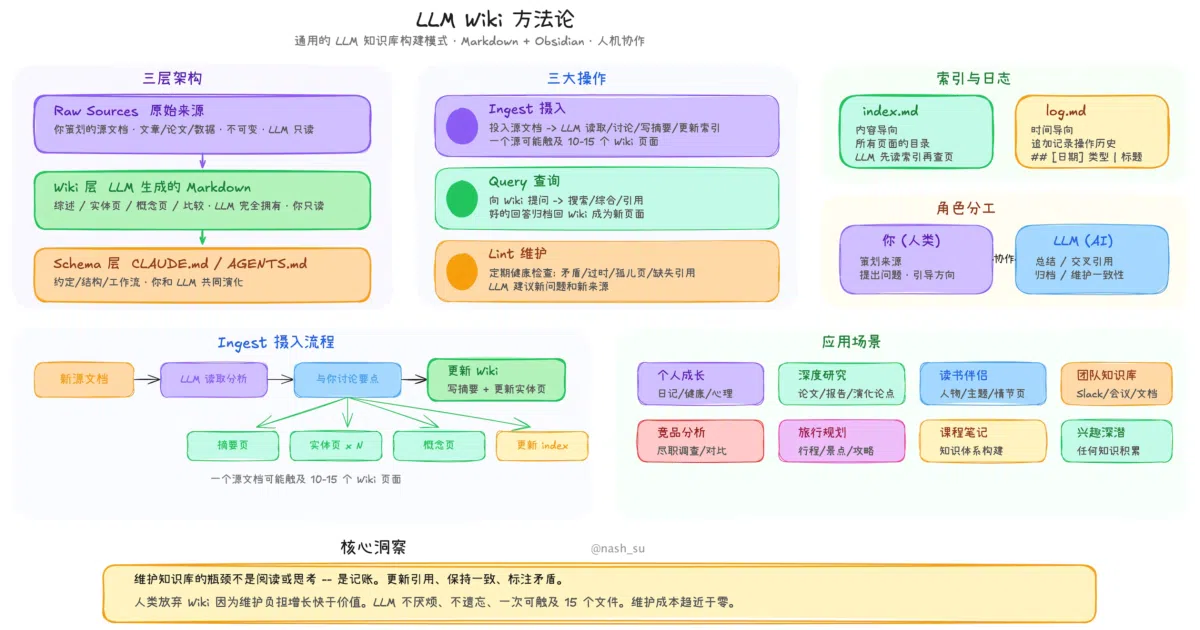
LLM Wiki is a cross-platform desktop app that ingests your documents and incrementally generates a structured wiki with [[wikilinks]], YAML frontmatter, and an auto-updated index. It treats your raw files as immutable sources and compiles them into a browsable knowledge graph that persists between sessions, rather than re-deriving answers from scratch on every query. The output is an Obsidian-compatible vault of Markdown files, so you own the artifacts and can abandon the app whenever you like.
The interesting bit
The project takes Andrej Karpathy’s abstract “LLM Wiki” gist—a copy-paste blueprint for LLM agents—and hardens it into a full desktop application with a three-column GUI, a sigma.js knowledge graph, and a two-phase ingest pipeline where the LLM first analyzes a document and then generates pages. It also adds a purpose.md file that acts as the wiki’s “soul,” giving the LLM directional intent during every ingest and query, which is a neat structural hack to keep a growing knowledge base from drifting into generic summarization.
Key highlights
- Two-step ingest: The LLM analyzes sources for entities, contradictions, and connections before generating wiki pages, with SHA256 caching to skip unchanged files.
- Knowledge graph engine: A 4-signal relevance model (direct links, source overlap, Adamic-Adar, type affinity) powers an interactive graph with Louvain community detection and cohesion scoring.
- Graph insights: Automatically flags surprising cross-community links, isolated pages, sparse clusters, and bridge nodes, with one-click “Deep Research” to fill gaps via web search.
- Agent-ready: Exposes a local JSON API and a ready-made skill for Claude Code / Codex, so external agents can search, traverse the graph, and rescan sources.
- Multimodal and connected: Extracts images from PDFs with vision-LLM captions, watches source folders for external changes, and includes a Chrome web clipper.
Verdict
Researchers, students, or anyone drowning in PDFs who wants a structured, browsable wiki rather than a chatbot interface should look here; if you just need a quick answer from a single document, traditional RAG is probably less overhead.
Frequently asked
- What is nashsu/llm_wiki?
- It turns your document pile into a persistent, interlinked wiki so the LLM doesn't have to re-read everything every time you ask a question.
- Is llm_wiki open source?
- Yes — nashsu/llm_wiki is an open-source project tracked on heatdrop.
- What language is llm_wiki written in?
- nashsu/llm_wiki is primarily written in TypeScript.
- How popular is llm_wiki?
- nashsu/llm_wiki has 15.1k stars on GitHub and is currently cooling off.
- Where can I find llm_wiki?
- nashsu/llm_wiki is on GitHub at https://github.com/nashsu/llm_wiki.