mit-han-lab/streaming-llm
Your chatbot can run forever if it forgets most of the chat
It lets standard LLMs handle infinite-length inputs without expanding their context window or exhausting memory.
Not currently ranked — collecting fresh signals.
star history
What it does
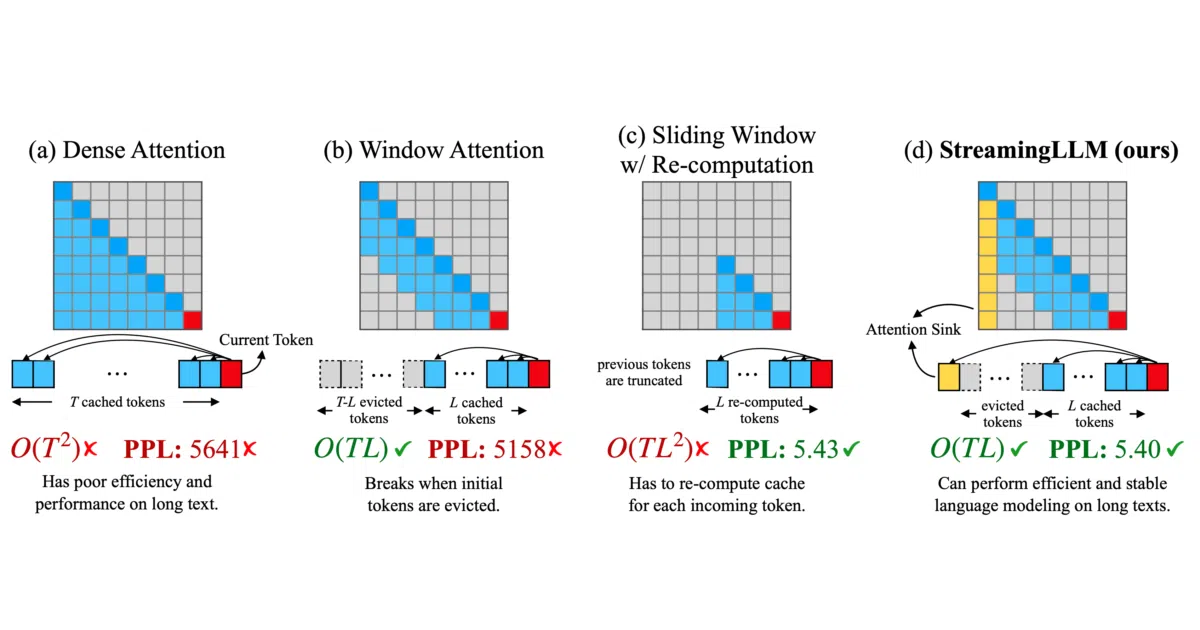
StreamingLLM is a framework for running LLMs on unbounded text streams. Instead of storing every previous token’s Key and Value states—which eventually devours memory—it caches only the very first tokens (dubbed “attention sinks”) and the most recent tokens in a fixed-size window. Everything in between is thrown away, allowing models like Llama-2, MPT, Falcon, and Pythia to generate text continuously without cache resets or recomputation. The authors report stable runs up to 4 million tokens and up to a 22.2× speedup over sliding-window recomputation in streaming settings.
The interesting bit
The trick relies on a quirk of transformer attention: initial tokens act as an inexplicable “sink” for attention scores even when they carry no semantic weight. Evicting them causes window-attention to collapse, but keeping just those first few anchors rescues performance. It is a delightfully cheap hack—no fine-tuning required, just selective amnesia for the middle of the conversation.
Key highlights
- Works out-of-the-box on Llama-2, MPT, Falcon, and Pythia with no fine-tuning.
- Claims up to 4 million tokens processed and a 22.2× speedup over recomputation baselines in streaming scenarios.
- Adopted by HuggingFace Transformers, NVIDIA TensorRT-LLM, Intel Extension for Transformers, and SwiftInfer.
- Includes a reference chatbot demo and perplexity evaluation code.
- The authors note it is orthogonal to context-extension methods and can be combined with them.
Caveats
- It does not expand the model’s context window; it only retains the latest tokens plus the initial sinks, so long-range reasoning across a book or document is impossible.
- The model effectively forgets the middle of the conversation, making it unsuitable for tasks requiring memory of distant prior context.
- The StreamEval dataset and its evaluation code remain unreleased according to the repository’s TODO list.
Verdict
Anyone building perpetual chatbots, live log processors, or other streaming assistants where recent context matters most should look here. If you need genuine long-context memory or book-length summarization, this is the wrong tool—it explicitly throws away the middle.
Frequently asked
- What is mit-han-lab/streaming-llm?
- It lets standard LLMs handle infinite-length inputs without expanding their context window or exhausting memory.
- Is streaming-llm open source?
- Yes — mit-han-lab/streaming-llm is open source, released under the MIT license.
- What language is streaming-llm written in?
- mit-han-lab/streaming-llm is primarily written in Python.
- How popular is streaming-llm?
- mit-han-lab/streaming-llm has 7.2k stars on GitHub.
- Where can I find streaming-llm?
- mit-han-lab/streaming-llm is on GitHub at https://github.com/mit-han-lab/streaming-llm.