mit-han-lab/smoothquant
SmoothQuant makes LLM activation outliers the weights’ problem
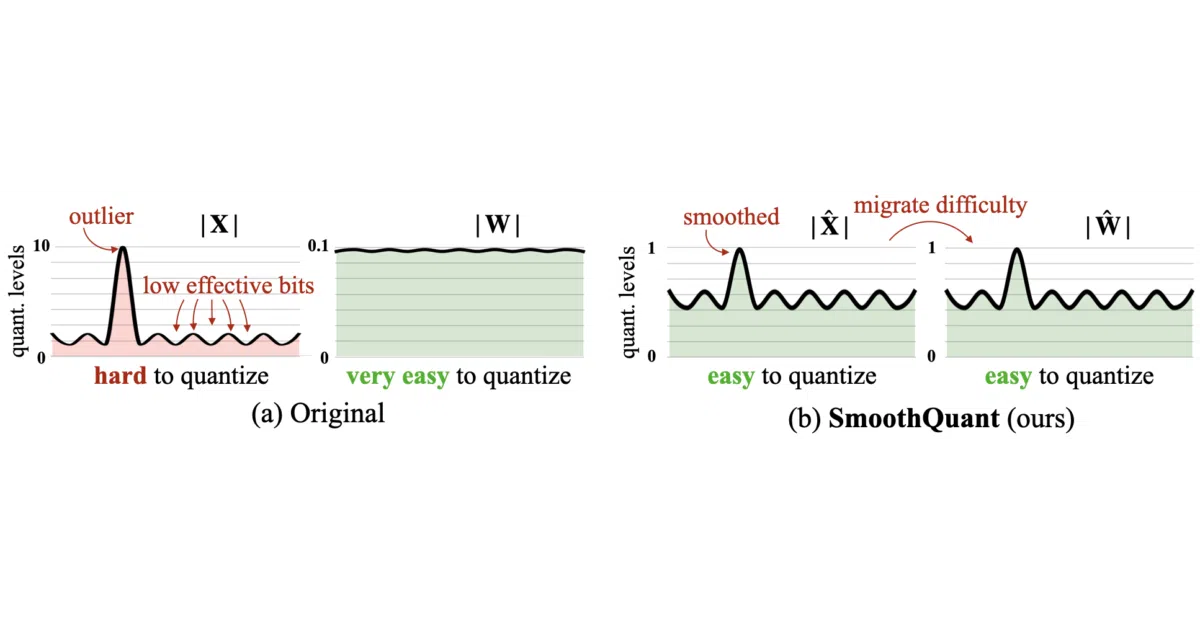
It migrates the quantization difficulty from unruly activations to more cooperative weights, enabling training-free W8A8 inference for massive language models.
Not currently ranked — collecting fresh signals.
star history
What it does\nSmoothQuant is a post-training quantization method that squeezes both weights and activations of large language models down to 8-bit integers. It handles the spiky activation distributions that normally sabotage low-bit quantization on models like OPT-175B and Llama-2-70B. The repository provides PyTorch reference code, pre-quantized HuggingFace checkpoints for OPT, and ready-made calibration scales for Llama, Mistral, Falcon, Mixtral, and BLOOM.\n\nThe interesting bit\nRather than clamping volatile activation distributions into INT8 directly, the method applies a mathematically equivalent transformation that offloads the compression burden onto the weights, which tolerate quantization far better. The entire model then runs in fast INT8 GEMMs without retraining and without the accuracy collapse typical of naive baselines.\n\nKey highlights\n* Achieves W8A8 quantization on models up to 530B parameters with negligible perplexity loss compared to FP16, according to the reported benchmarks.\n* Integrated into major serving stacks including NVIDIA TensorRT-LLM, FasterTransformer, ONNX Runtime, and Amazon SageMaker; AMD MI300X support arrived in 2024.\n* The reference PyTorch implementation uses custom torch-int CUTLASS kernels and demonstrates up to 1.56× speedup and 2× memory reduction over FP16.\n* Provides ready-made activation channel scales derived from 512 Pile validation sentences, plus scripts to generate your own for new models.\n* Pre-smoothed INT8 OPT models from 125M to 66B are hosted directly on HuggingFace.\n\nCaveats\n* The authors explicitly recommend NVIDIA TensorRT-LLM or FasterTransformer for measured speedup, suggesting the native PyTorch code is more of a research reference than a production runtime.\n* Real INT8 inference in the bundled PyTorch demo is shown only up to OPT-30B on a single A100; larger deployments require multi-GPU setups via FasterTransformer.\n\nVerdict\nIf you are serving LLMs at scale and need to halve GPU memory and count without retraining, this is a proven quantization recipe worth evaluating. If you want a single drop-in INT8 runtime that works out of the box for every architecture, you will likely spend time bridging into framework-specific integrations instead.
Frequently asked
- What is mit-han-lab/smoothquant?
- It migrates the quantization difficulty from unruly activations to more cooperative weights, enabling training-free W8A8 inference for massive language models.
- Is smoothquant open source?
- Yes — mit-han-lab/smoothquant is open source, released under the MIT license.
- What language is smoothquant written in?
- mit-han-lab/smoothquant is primarily written in Python.
- How popular is smoothquant?
- mit-han-lab/smoothquant has 1.7k stars on GitHub.
- Where can I find smoothquant?
- mit-han-lab/smoothquant is on GitHub at https://github.com/mit-han-lab/smoothquant.