mishushakov/llm-scraper
Scraping by asking nicely, then asking again in JSON
A TypeScript library that feeds webpages to LLMs and gets structured data back via Zod schemas.
Not currently ranked — collecting fresh signals.
star history
What it does
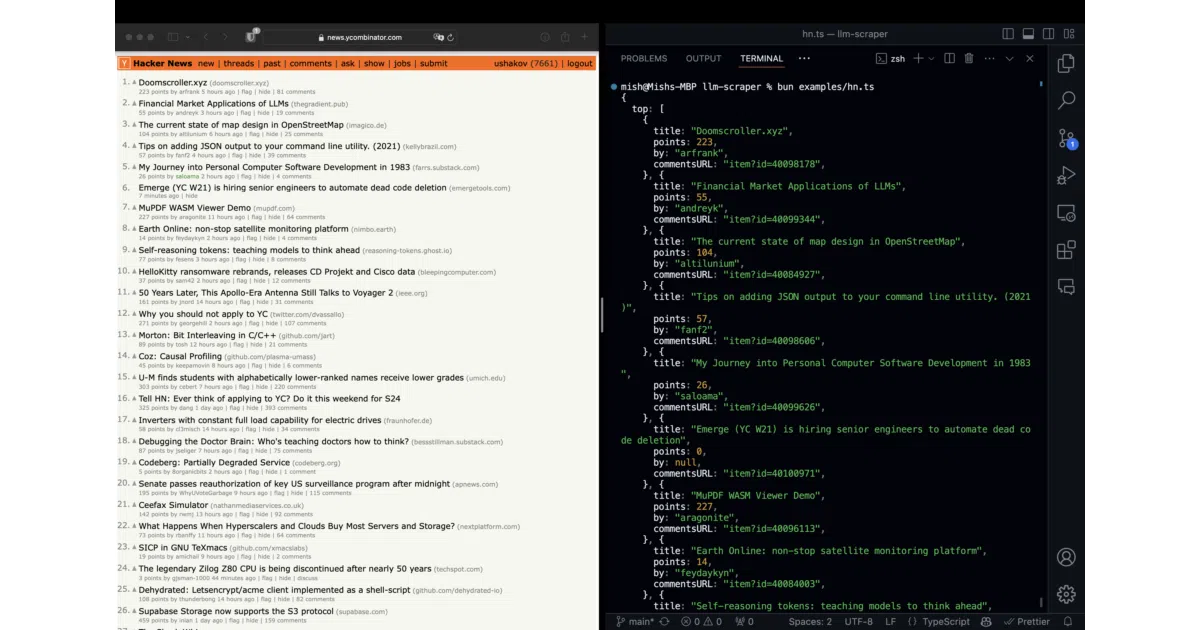
LLM Scraper is a TypeScript wrapper around Playwright that sends webpage content—HTML, markdown, extracted text, or even screenshots—to an LLM and asks for structured output matching a Zod or JSON Schema. You define the shape; the model fills it in. It supports GPT-4o, Claude, Gemini, Llama, Qwen, and others via the Vercel AI SDK.
The interesting bit
The generate mode is the clever twist: instead of burning tokens on every scrape, you can ask the LLM to write a Playwright script that extracts the data deterministically. One expensive call, then cheap reuse. It is the rare LLM tool that tries to make itself obsolete.
Key highlights
- Six input formats including Readability.js-cleaned text and screenshot-to-multimodal
- Streaming partial objects for real-time UI updates
- Full TypeScript type-safety from schema to result
- Works with local models via Ollama, not just cloud APIs
Caveats
- The README shows no benchmarks, cost estimates, or accuracy comparisons versus traditional scraping—token costs on large pages are unclear
- Code generation quality depends heavily on the model; no fallback if the generated Playwright script fails
Verdict
Worth a look if you maintain brittle scrapers that break on every redesign, or need to extract semantic data from sites without clean APIs. Skip it if you are scraping at volume and need predictable latency or cost.
Frequently asked
- What is mishushakov/llm-scraper?
- A TypeScript library that feeds webpages to LLMs and gets structured data back via Zod schemas.
- Is llm-scraper open source?
- Yes — mishushakov/llm-scraper is open source, released under the MIT license.
- What language is llm-scraper written in?
- mishushakov/llm-scraper is primarily written in TypeScript.
- How popular is llm-scraper?
- mishushakov/llm-scraper has 6.9k stars on GitHub.
- Where can I find llm-scraper?
- mishushakov/llm-scraper is on GitHub at https://github.com/mishushakov/llm-scraper.