microsoft/Swin-Transformer
A vision transformer that actually looks at windows
Microsoft's official Swin Transformer implementation brings hierarchical attention to computer vision by computing self-attention in shifted local windows rather than across entire images.
Not currently ranked — collecting fresh signals.
star history
What it does
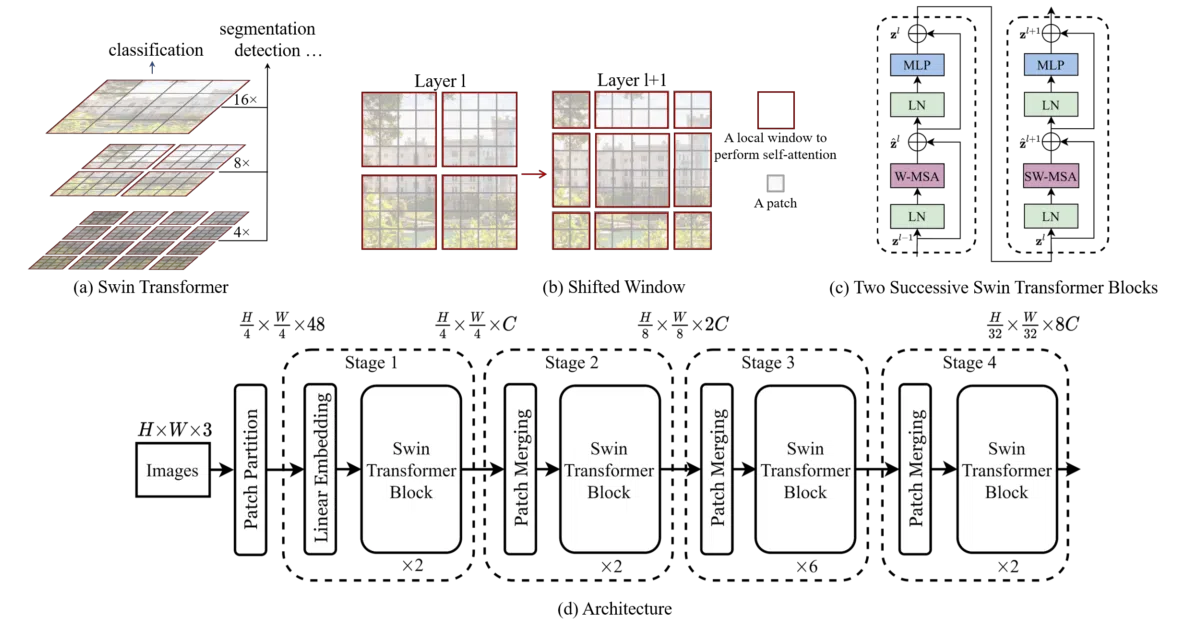
Swin Transformer is a general-purpose vision backbone that processes images through hierarchical Transformer layers using a “shifted window” scheme. Instead of running self-attention across an entire image (expensive), it limits attention computation to small non-overlapping local windows, then shifts those windows in alternating layers to allow cross-window connections. The repo includes code and pretrained models for image classification; related repos handle object detection, semantic segmentation, video action recognition, and more.
The interesting bit
The shifted window trick is the whole pitch: it’s how you get the long-range modeling power of Transformers without the quadratic cost of global attention. The name “Swin” literally stands for Shifted window. This won an ICCV 2021 best paper award (Marr Prize), which in computer vision is roughly equivalent to being named valedictorian of a very competitive high school.
Key highlights
- Pretrained models from Tiny (28M params) up to giant 1B-parameter SwinV2 variants, trained on ImageNet-1K and ImageNet-22K
- Nvidia FasterTransformer integration for faster inference on T4 and A100 GPUs
- SimMIM masked image modeling support for self-supervised pre-training (40x less labeled data than prior billion-scale models, per the README)
- Swin-MoE variant using Microsoft’s Tutel library for sparse Mixture-of-Experts scaling
- Feature distillation add-on that pushed SwinV2-G to 61.4 mIoU on ADE20K semantic segmentation
Caveats
- The core repo only covers image classification; detection, segmentation, and video tasks live in separate repositories
- README contains broken links and typos (“new recrod,” “semi-supervisd”) that suggest maintenance has slowed since late 2022
- Baidu download links for model checkpoints may be unreliable for non-China users
Verdict
Worth studying if you’re building vision backbones or need a well-benchmarked Transformer architecture with proven transfer learning. Skip if you want a single-repo, batteries-included framework — this is a research reference implementation with satellites.
Frequently asked
- What is microsoft/Swin-Transformer?
- Microsoft's official Swin Transformer implementation brings hierarchical attention to computer vision by computing self-attention in shifted local windows rather than across entire images.
- Is Swin-Transformer open source?
- Yes — microsoft/Swin-Transformer is open source, released under the MIT license.
- What language is Swin-Transformer written in?
- microsoft/Swin-Transformer is primarily written in Python.
- How popular is Swin-Transformer?
- microsoft/Swin-Transformer has 16k stars on GitHub.
- Where can I find Swin-Transformer?
- microsoft/Swin-Transformer is on GitHub at https://github.com/microsoft/Swin-Transformer.