lvapeab/nmt-keras
Keras NMT toolkit that predates the hype cycle
A research-grade neural machine translation framework built before Transformers ate the world, still supporting RNNs, attention variants, and interactive translation.
Not currently ranked — collecting fresh signals.
star history
What it does
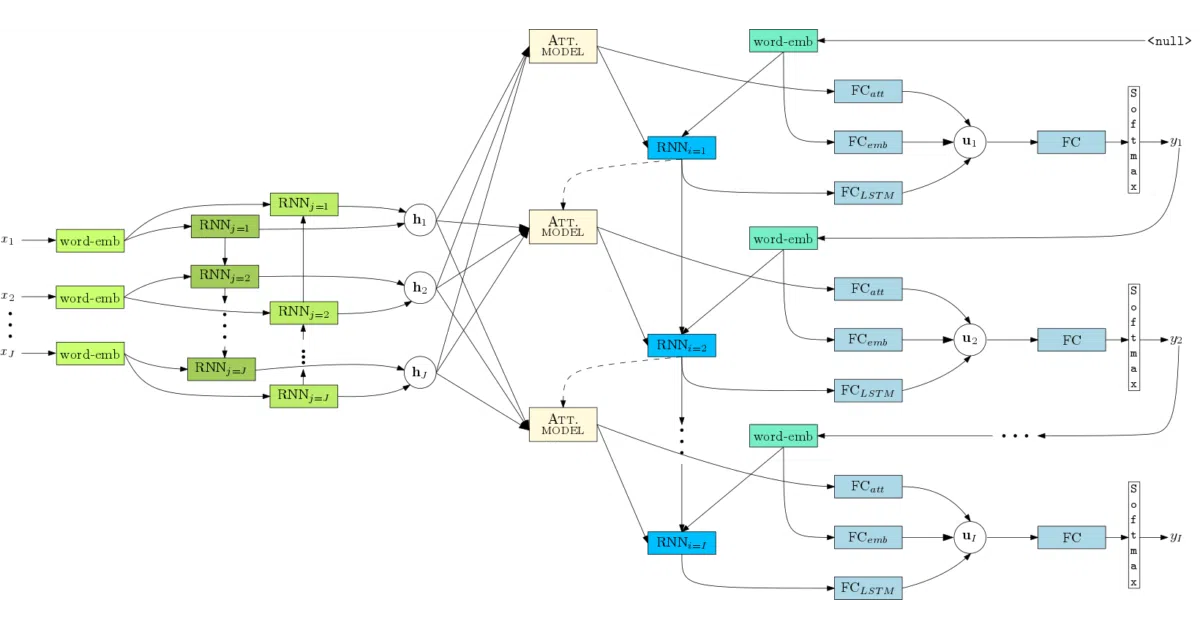
NMT-Keras is a neural machine translation library built on a forked Keras 2.0.7+ and a custom multimodal wrapper. It trains and runs seq2seq models—RNN-based with Bahdanau or Luong attention, plus a Transformer implementation—through a config.py and main.py workflow. Decoding supports beam search, ensemble averaging, length normalization, and n-best list generation.
The interesting bit
The project doubles as a research vehicle for interactive and online NMT: there’s a whole branch for protocols where human translators collaborate with the model in real time, plus a client-server web demo. That’s unusual depth for a Keras-era toolkit, and the authors published on it.
Key highlights
- Supports both attentional RNNs (GRU/LSTM, conditional variants, residual stacks) and Transformer architectures
- Multi-GPU training (TensorFlow only), TensorBoard logging, and label smoothing
- Pretrained embeddings (GloVe, Word2Vec), unknown-word replacement, and model averaging
- Interactive NMT branch with online learning; live web demo at
casmacat.prhlt.upv.es/inmt - Two Colab notebooks for tutorial and model-dissection walkthroughs
Caveats
- Requires a specific fork of Keras (
MarcBS/keras) and a companionmultimodal_keras_wrapper—not stock dependencies - Theano backend is untested and throws a known, non-fatal
InconsistencyError - Python 3.7 badge suggests the codebase hasn’t tracked the ecosystem forward
Verdict
Worth a look if you’re reproducing older NMT papers, studying interactive translation interfaces, or need a hackable Keras-era baseline. Skip it if you want production-scale training with modern PyTorch or JAX stacks.
Frequently asked
- What is lvapeab/nmt-keras?
- A research-grade neural machine translation framework built before Transformers ate the world, still supporting RNNs, attention variants, and interactive translation.
- Is nmt-keras open source?
- Yes — lvapeab/nmt-keras is open source, released under the MIT license.
- What language is nmt-keras written in?
- lvapeab/nmt-keras is primarily written in Python.
- How popular is nmt-keras?
- lvapeab/nmt-keras has 532 stars on GitHub.
- Where can I find nmt-keras?
- lvapeab/nmt-keras is on GitHub at https://github.com/lvapeab/nmt-keras.