lucidrains/local-attention
Why your transformer’s bottom layers need blinders
A drop-in PyTorch implementation of local windowed attention, built on the idea that bottom layers should focus locally while top layers handle the global picture.
Not currently ranked — collecting fresh signals.
star history
What it does
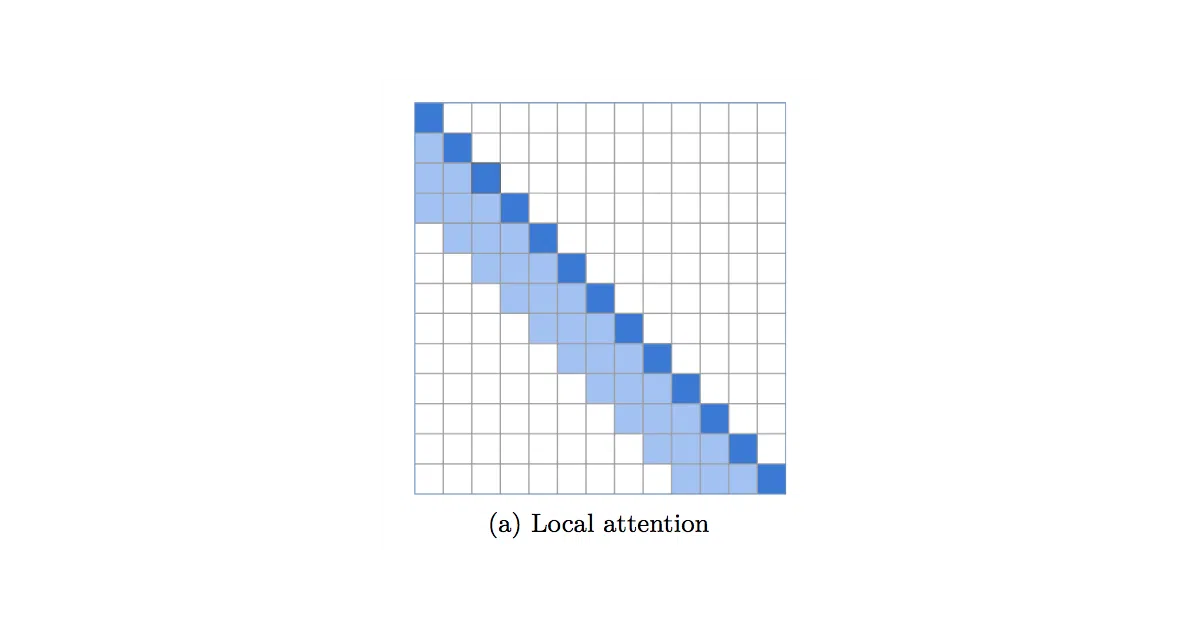
local-attention is a PyTorch utility that caps each token’s view to a fixed-size neighborhood instead of the full sequence, turning quadratic self-attention into something linear in practice. It supports causal autoregressive masking, shared query-key tensors, and an autopad flag for sequences that do not line up with the window size. If you need more than a single block, it also ships a ready-made LocalTransformer.
The interesting bit
The README advances a specific architectural opinion: transformers should keep local attention in the bottom layers and reserve global attention for the top layers to integrate findings. That is more design philosophy than a generic speed hack. It also handles the annoying masking and normalization details when query and key share the same space, which often trip up home-brew implementations.
Key highlights
- Sliding-window attention with independent
look_backwardandlook_forwardcontrols. - Causal and non-causal modes, plus Reformer-style shared Q/K with self-token masking handled.
autopadto quietly fix sequence lengths that are not multiples of the window size.- A full
LocalTransformermodel class, not just an attention layer. - Claims to be “battletested” alongside other sparse long-range attention implementations.
Verdict
Grab this if you are prototyping long-context language models and want a drop-in sliding-window attention block without writing masking logic by hand. Look elsewhere if you need a complete training framework or built-in benchmark results—the README calls it an “incredibly strong baseline” but does not show the numbers.
Frequently asked
- What is lucidrains/local-attention?
- A drop-in PyTorch implementation of local windowed attention, built on the idea that bottom layers should focus locally while top layers handle the global picture.
- Is local-attention open source?
- Yes — lucidrains/local-attention is open source, released under the MIT license.
- What language is local-attention written in?
- lucidrains/local-attention is primarily written in Python.
- How popular is local-attention?
- lucidrains/local-attention has 503 stars on GitHub.
- Where can I find local-attention?
- lucidrains/local-attention is on GitHub at https://github.com/lucidrains/local-attention.