lucidrains/RETRO-pytorch
GPT-3's punch at 1/10th the weight, via a library card
RETRO augments a small transformer with a retrieval database, trading brute-force scale for actual memory.
Not currently ranked — collecting fresh signals.
star history
What it does
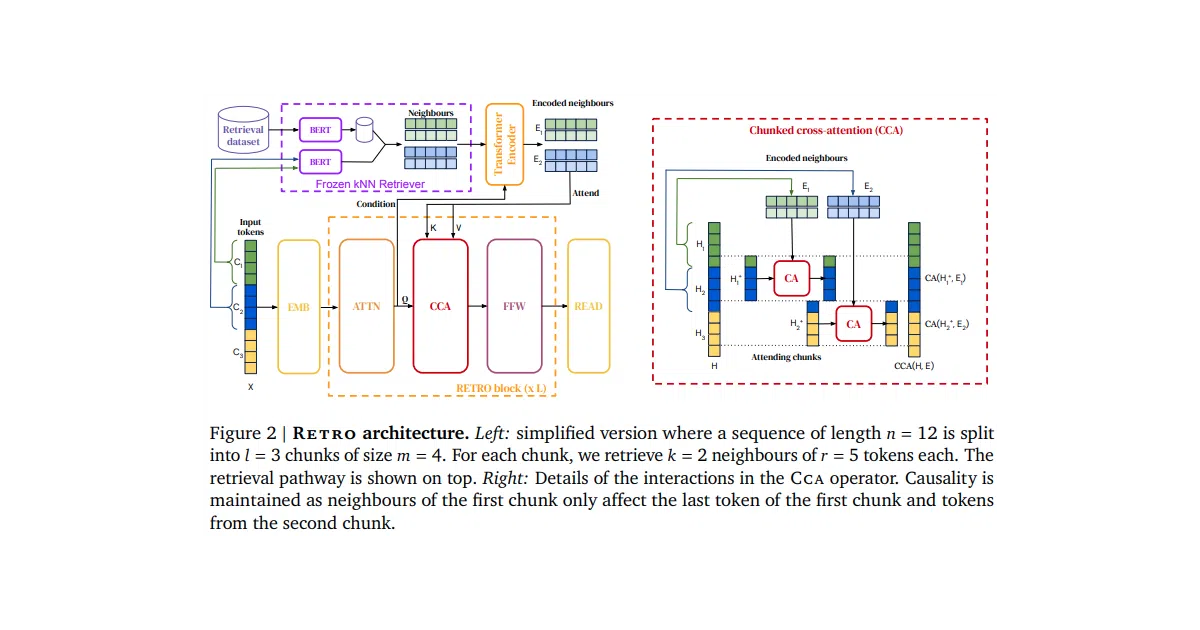
RETRO (Retrieval-Enhanced Transformer) pairs a standard decoder with a chunky external memory. During training and generation, it fetches relevant text snippets from a pre-built index and attends over them, letting a ~800M-parameter model punch near GPT-3 territory. This repo implements the full stack: model, training wrapper, FAISS indexing, and BERT-based chunk embedding.
The interesting bit
The cleverness is in the causal chunked cross-attention: the decoder only retrieves at chunk boundaries, so generation stays autoregressive while the model “looks up” facts it was never big enough to memorize. The author also swaps the paper’s ScaNN for FAISS and adds optional DeepNet scaling (now validated at 130B) for anyone feeling ambitious enough to stack 1,000 layers.
Key highlights
- End-to-end pipeline: raw text → BERT embeddings → FAISS index → memmapped training arrays
TrainingWrapperhandles the gnarly data prep (chunking, neighbor precomputation, document-id filtering to avoid trivial same-doc matches)- Optional
use_deepnetflag for DeepNet-style initialization and scaling - Built on
autofaissfor index construction with memory-constrained settings - Rotary positional embeddings substituted for the paper’s relative encoding
Caveats
- README notes this “deviates from the paper slightly”; exact reproduction fidelity is unclear
- No training results, loss curves, or downstream benchmarks shown in the repo
- The 10× parameter claim is cited from the paper, not independently verified here
Verdict
Worth a look if you’re experimenting with retrieval-augmented generation or want to train a competent language model on modest GPU budgets. Skip if you need a battle-tested, production-scale system—this is research scaffolding with sharp edges.
Frequently asked
- What is lucidrains/RETRO-pytorch?
- RETRO augments a small transformer with a retrieval database, trading brute-force scale for actual memory.
- Is RETRO-pytorch open source?
- Yes — lucidrains/RETRO-pytorch is open source, released under the Apache-2.0 license.
- What language is RETRO-pytorch written in?
- lucidrains/RETRO-pytorch is primarily written in Python.
- How popular is RETRO-pytorch?
- lucidrains/RETRO-pytorch has 879 stars on GitHub.
- Where can I find RETRO-pytorch?
- lucidrains/RETRO-pytorch is on GitHub at https://github.com/lucidrains/RETRO-pytorch.