lmmlzn/Awesome-LLMs-Datasets
A Field Guide to the 444 Datasets Feeding Modern LLMs
A curated index that maps the training corpora, instruction sets, and evaluation benchmarks serving as the foundational infrastructure for large language models.
Not currently ranked — collecting fresh signals.
star history
What it does
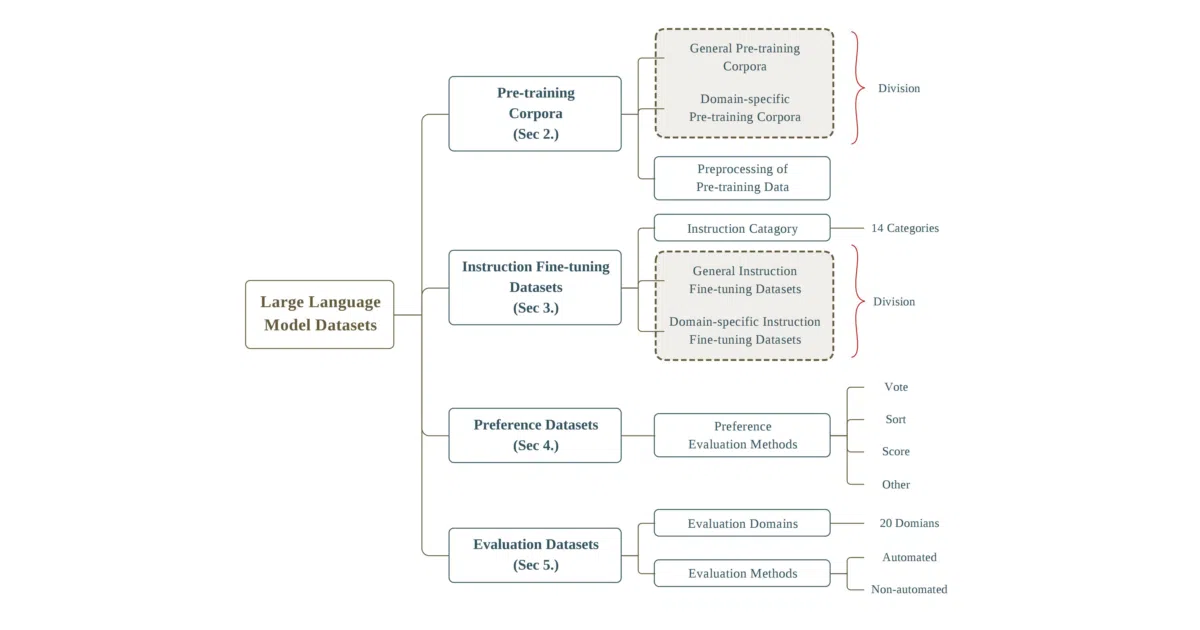
This repository is a curated reference index and companion to the survey paper Datasets for Large Language Models. It catalogues hundreds of datasets used for pre-training, fine-tuning, preference alignment, and evaluation, organizing them into standardized categories with detailed metadata. The project recently expanded beyond text to include multi-modal LLM and RAG datasets.
The interesting bit
Instead of a typical awesome-list, the maintainers treat dataset metadata as a first-class citizen. Every entry is normalized across 20 dimensions—construction method, license, public availability, language, and evaluation methodology—turning a bibliography into a structured research database. The schema has been applied to 444 datasets across 32 domains and 8 language categories, totaling over 774.5 TB of pre-training corpora and 700 million other instances.
Key highlights
- Covers 444 datasets spanning pre-training corpora, instruction-tuning data, preference pairs, evaluation benchmarks, and traditional NLP tasks
- Enforces a 20-dimension metadata module including construction method (
HG,MC,CI), license, and public-access status - Companion to the arXiv survey paper Datasets for Large Language Models: A Comprehensive Survey
- Recently added sections for Multi-modal LLM and Retrieval-Augmented Generation datasets
- Maintains a detailed public changelog; from 2025 onward updates will slim down to key details only
Caveats
- Starting in 2025, updates are narrowed to essential details like dataset name and paper link, pushing deeper statistics back to the original papers
- This is a signpost and survey tool, not a data repository—actual downloads and usage depend on external sources with varying licenses
Verdict
Researchers and data engineers hunting for training or evaluation data should treat this as a comprehensive field guide. If you are looking for ready-to-ingest data bundles or code frameworks, this is just the bibliography—albeit an unusually thorough one.
Frequently asked
- What is lmmlzn/Awesome-LLMs-Datasets?
- A curated index that maps the training corpora, instruction sets, and evaluation benchmarks serving as the foundational infrastructure for large language models.
- Is Awesome-LLMs-Datasets open source?
- Yes — lmmlzn/Awesome-LLMs-Datasets is open source, released under the Apache-2.0 license.
- How popular is Awesome-LLMs-Datasets?
- lmmlzn/Awesome-LLMs-Datasets has 1.5k stars on GitHub.
- Where can I find Awesome-LLMs-Datasets?
- lmmlzn/Awesome-LLMs-Datasets is on GitHub at https://github.com/lmmlzn/Awesome-LLMs-Datasets.