liucongg/GPT2-NewsTitle
A GPT2 tutorial disguised as a headline generator
A Chinese-language learning project that admits its own model is undertrained because the author couldn't afford GPUs.
Not currently ranked — collecting fresh signals.
star history
What it does
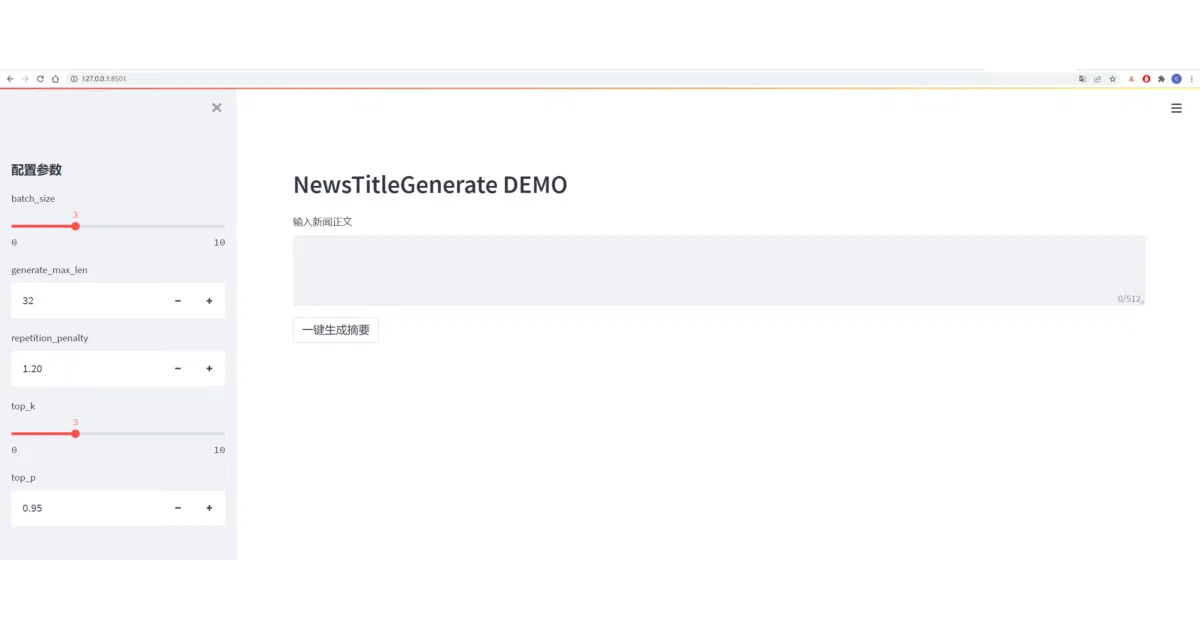
This repo walks you through training a GPT-2 model to generate Chinese news headlines from article text. It includes data preprocessing, training scripts, a custom vocabulary with special tokens like [Content] and [Title], and both Flask and Streamlit frontends so you can demo the results in a browser without touching HTML.
The interesting bit
The author is refreshingly honest: the bundled model is only 6 layers, randomly initialized (no pretrained weights), and trained for just 5 epochs because, in their words, “穷人没人卡” — poor people don’t have GPUs. The real product isn’t the model; it’s the heavily commented code meant to teach the full pipeline from data cleaning to deployment.
Key highlights
- Extensive Chinese comments explaining each step of GPT-2 training, loss computation, and generation
- Curated collection of 10+ Chinese news/summarization datasets (THUCTC, Sogou, LCSTS, etc.) with Baidu Pan download links
- Custom loss function that only computes loss on the title portion, not the full article
- Both Flask and Streamlit UIs included; the Streamlit addition is recent (Feb 2022)
- Vocabulary trimmed to 13,317 tokens with special markers for content/title boundaries
Caveats
- The provided model is explicitly described as undertrained and “效果一般” (mediocre); you’ll need to train your own for production use
- All dataset and model downloads use Baidu Pan, which requires extraction codes and may be inaccessible outside China
- Dependencies are pinned to older versions (transformers 3.0.2, Flask 0.12.2)
Verdict
Worth bookmarking if you’re a Chinese-speaking developer who wants to understand GPT-2 mechanics hands-on. Skip it if you need a ready-to-use headline generator; the author will tell you themselves this isn’t that.
Frequently asked
- What is liucongg/GPT2-NewsTitle?
- A Chinese-language learning project that admits its own model is undertrained because the author couldn't afford GPUs.
- Is GPT2-NewsTitle open source?
- Yes — liucongg/GPT2-NewsTitle is open source, released under the Apache-2.0 license.
- What language is GPT2-NewsTitle written in?
- liucongg/GPT2-NewsTitle is primarily written in Python.
- How popular is GPT2-NewsTitle?
- liucongg/GPT2-NewsTitle has 1.1k stars on GitHub.
- Where can I find GPT2-NewsTitle?
- liucongg/GPT2-NewsTitle is on GitHub at https://github.com/liucongg/GPT2-NewsTitle.