liruilong940607/prope
Relative camera geometry inside attention layers
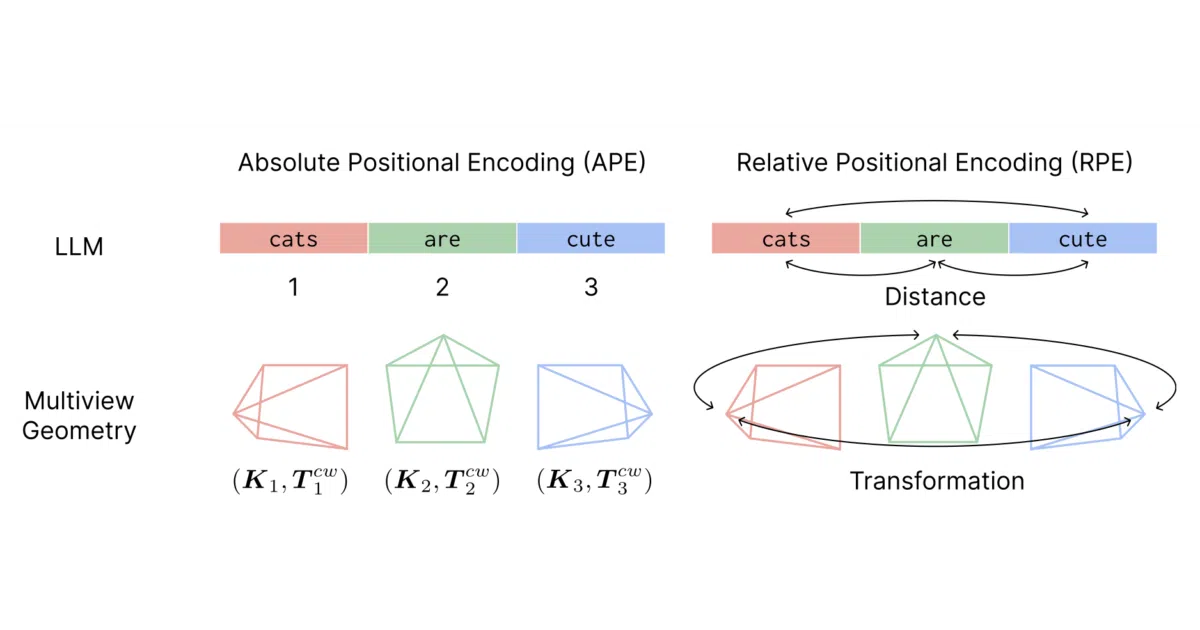
PRoPE lets multi-view transformers infer 3D spatial relationships by injecting camera matrices directly into scaled dot-product attention.
Not currently ranked — collecting fresh signals.
star history
What it does
PRoPE is a drop-in replacement for standard scaled dot-product attention that conditions on camera intrinsics and extrinsics. Instead of preprocessing absolute raymaps or relative pose embeddings, it bakes the relative projective transformation between views directly into the attention scores. The result is a geometry-aware token interaction that understands where each patch sits in 3D space relative to other cameras.
The interesting bit
The entire implementation fits in a single file for both PyTorch and JAX—no sprawling modules, no custom CUDA kernels. It accepts viewmats and Ks alongside your Q/K/V tensors, and the attention mechanism handles the rest. It is already shipping in production systems like Tencent’s Hunyuan World Model 1.5, which suggests the overhead is negligible enough for generative world models.
Key highlights
- Standalone single-file implementations in
prope/torch.pyandprope/jax.py - Drop-in API intended to replace
torch.nn.functional.scaled_dot_product_attention - Claims improvement over LVSM for novel view synthesis (see
nvsbranch) - Adopted by Tencent Hunyuan World Model 1.5 for camera control
- Extended by follow-up work for distorted cameras and feed-forward reconstruction
Caveats
- Stereo depth estimation experiments with UniMatch are noted as “to be released”
- The README frames the method as a study comparing absolute, relative pose, and projective encodings, so the gains may be task-dependent
Verdict
Worth a look if you are building multi-view transformers and want camera conditioning without architectural surgery. Skip it if you are not working with calibrated multi-camera setups.
Frequently asked
- What is liruilong940607/prope?
- PRoPE lets multi-view transformers infer 3D spatial relationships by injecting camera matrices directly into scaled dot-product attention.
- Is prope open source?
- Yes — liruilong940607/prope is an open-source project tracked on heatdrop.
- What language is prope written in?
- liruilong940607/prope is primarily written in Python.
- How popular is prope?
- liruilong940607/prope has 741 stars on GitHub.
- Where can I find prope?
- liruilong940607/prope is on GitHub at https://github.com/liruilong940607/prope.