linkedin/Liger-Kernel
Drop-in Triton kernels that make LLM training stop choking on memory
LinkedIn's open-source collection fuses and chunks standard transformer layers so you can train bigger models on the same GPUs without touching your modeling code.
Not currently ranked — collecting fresh signals.
star history
What it does
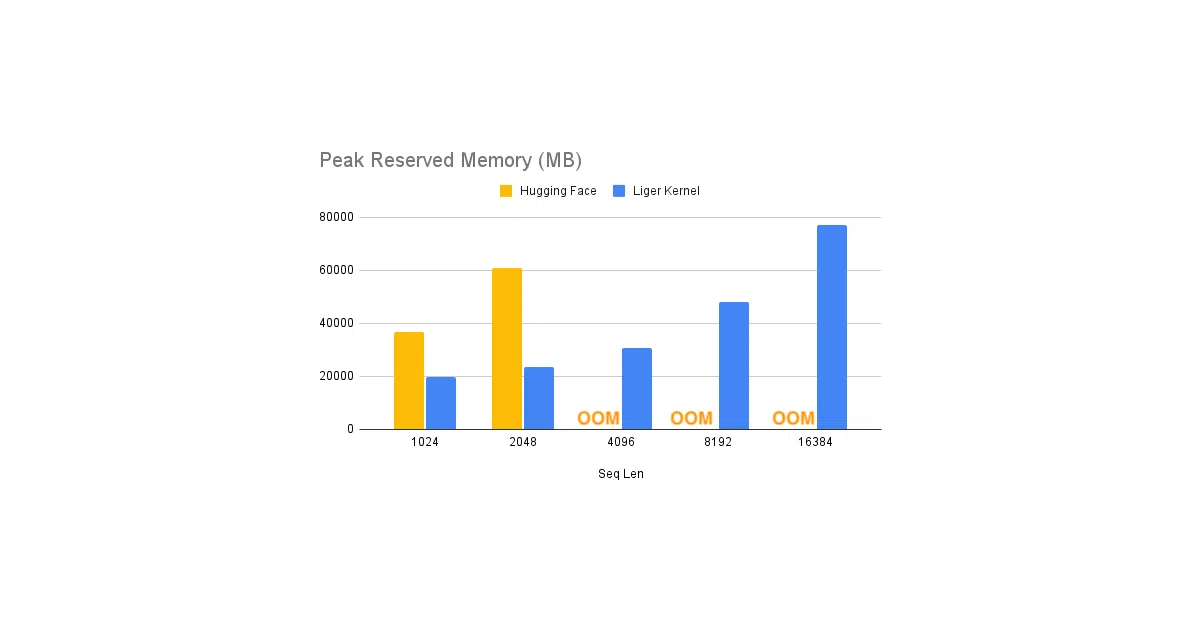
Liger Kernel is a library of hand-written Triton kernels for the unglamorous but memory-hungry parts of LLM training—RMSNorm, RoPE, SwiGLU, CrossEntropy, and a growing list of post-training losses like DPO and ORPO. You patch a Hugging Face model in one line (AutoLigerKernelForCausalLM) or import the kernels directly. It runs alongside Flash Attention, FSDP, and DeepSpeed without ceremony.
The interesting bit The project treats kernel fusion as plumbing, not research. By fusing operations, replacing tensors in-place, and chunking large computations, it claims 20% throughput gains and 60% memory reduction on standard LLaMA 3-8B runs. The post-training kernels go further—up to 80% memory savings for alignment losses—because the authors noticed everyone was quietly OOMing during DPO. It is exact, not approximate: they unit-test and convergence-test against vanilla PyTorch.
Key highlights
- One-line monkey-patch for Hugging Face models, or compose kernels à la carte
- Exact numerical parity with PyTorch; no approximations
- Supports CUDA and ROCm; minimal dependencies (just torch and triton)
- Integrates with Axolotl, LLaMA-Factory, HF Trainer, Lightning, and others
- Optional cuTile backend for environments with CUDA Toolkit 13.1+
Caveats
- Benchmarks shown are specific: LLaMA 3-8B, bf16, AdamW, gradient checkpointing, FSDP1 on 8×A100s; your mileage will vary
- The
AutoLigerKernelForCausalLMwrapper only works for supported model types; unsupported architectures need manual kernel composition - cuTile backend is opt-in and raises hard errors if dependencies or hardware mismatch
Verdict Worth a look if you are fine-tuning or aligning LLMs and have already squeezed what you can from Flash Attention and FSDP. Less compelling if you are training from scratch with a custom architecture not covered by the patching APIs.
Frequently asked
- What is linkedin/Liger-Kernel?
- LinkedIn's open-source collection fuses and chunks standard transformer layers so you can train bigger models on the same GPUs without touching your modeling code.
- Is Liger-Kernel open source?
- Yes — linkedin/Liger-Kernel is open source, released under the BSD-2-Clause license.
- What language is Liger-Kernel written in?
- linkedin/Liger-Kernel is primarily written in Python.
- How popular is Liger-Kernel?
- linkedin/Liger-Kernel has 6.5k stars on GitHub.
- Where can I find Liger-Kernel?
- linkedin/Liger-Kernel is on GitHub at https://github.com/linkedin/Liger-Kernel.