lightseekorg/tokenspeed
An inference engine that generates its own parallelism
TokenSpeed is a preview inference engine trying to deliver TensorRT-LLM-grade throughput for agentic workloads while keeping the ergonomics of vLLM.
Velocity · 7d
+8.4
★ / day
Trend
↗accelerating
star history
What it does
TokenSpeed is an LLM inference engine built for agentic workloads. It aims to match the throughput of TensorRT-LLM with an interface closer to vLLM. The current preview release is narrowly scoped to reproducing benchmark results for Kimi K2.5 and MLA kernels on NVIDIA B200 hardware.
The interesting bit Instead of asking users to hand-write collective communication for distributed inference, a static compiler generates parallelism logic from module-boundary placement annotations. The scheduler encodes request lifecycle and KV cache ownership as a finite-state machine, leaning on the type system to enforce safe KV cache reuse at compile time — a rare case where the compiler says “no” before you deploy.
Key highlights
- Local-SPMD modeling layer with compiler-generated collective communication
- C++ control plane / Python execution plane split
- Pluggable kernel registry including an MLA implementation tuned for Blackwell
SMG-integratedAsyncLLMentrypoint for low-overhead CPU request handling- Claims 580 TPS on
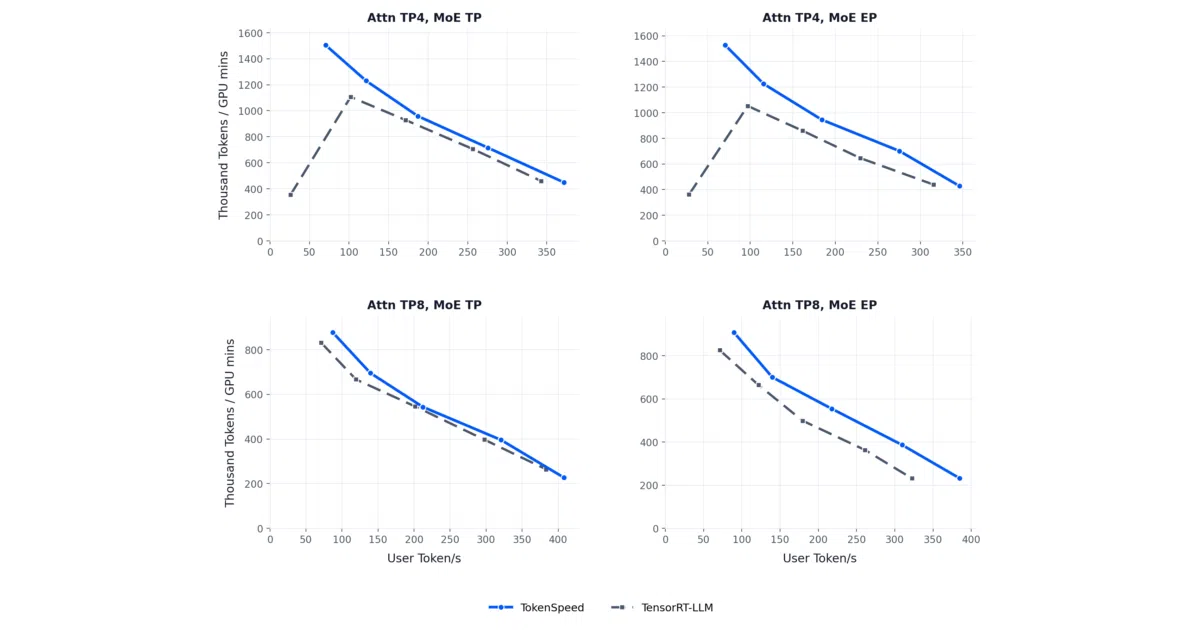
Qwen3.5-397B-A17Bfor agentic workloads (per project blog)
Caveats
- Explicitly a preview release; the README warns against production use
- Several major PRs are unmerged, so runtime features like PD, EPLB, KV store, VLM, and metrics are still incoming
- Current scope is narrow: mostly useful for reproducing the published Kimi K2.5 and MLA on B200 results
Verdict Worth watching if you run large-scale agentic inference on NVIDIA hardware and are tired of choosing between raw speed and developer ergonomics. Skip it if you need a stable, general-purpose engine today.
Frequently asked
- What is lightseekorg/tokenspeed?
- TokenSpeed is a preview inference engine trying to deliver TensorRT-LLM-grade throughput for agentic workloads while keeping the ergonomics of vLLM.
- Is tokenspeed open source?
- Yes — lightseekorg/tokenspeed is open source, released under the MIT license.
- What language is tokenspeed written in?
- lightseekorg/tokenspeed is primarily written in Python.
- How popular is tokenspeed?
- lightseekorg/tokenspeed has 1.6k stars on GitHub and is currently accelerating.
- Where can I find tokenspeed?
- lightseekorg/tokenspeed is on GitHub at https://github.com/lightseekorg/tokenspeed.