lightaime/deep_gcns_torch
How to train a GCN with 1,000 layers without it melting down
A research repo that borrows CNN tricks—residual connections, dilated convolutions—to make graph neural networks actually go deep.
Not currently ranked — collecting fresh signals.
star history
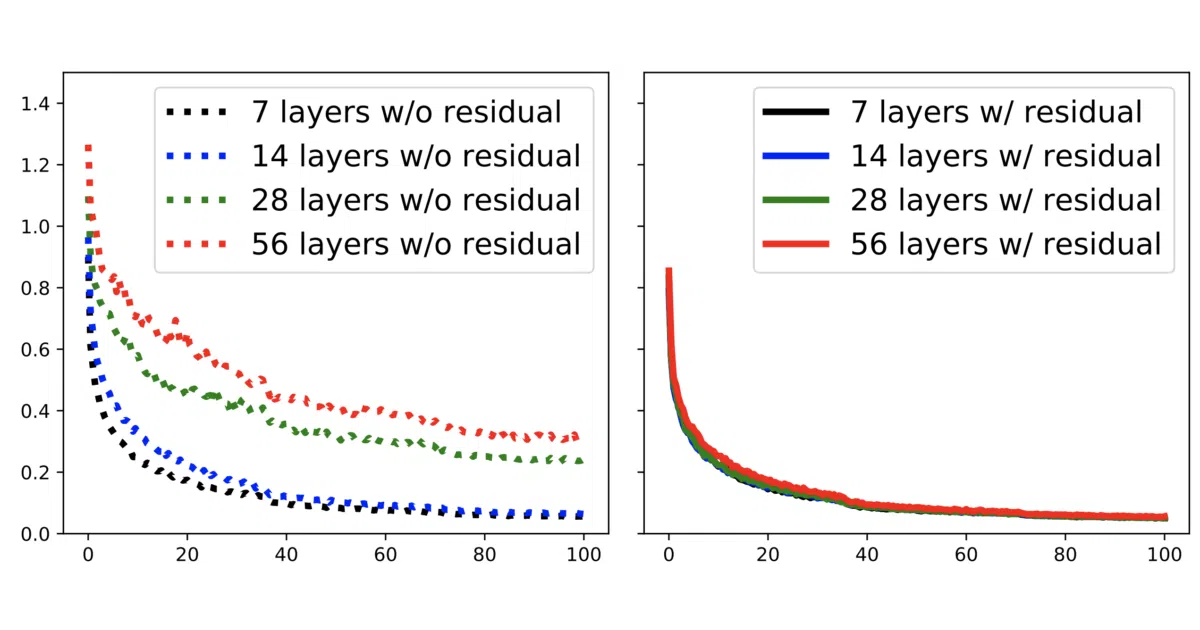
What it does This is the PyTorch implementation of DeepGCNs, DeeperGCN, and GNN1000, a series of papers that tackle a stubborn problem: graph convolutional networks usually degrade after a handful of layers. The repo adapts CNN staples—residual/dense connections and dilated convolutions—to graph architectures, then validates them across point cloud segmentation, node classification, and graph property prediction tasks.
The interesting bit The GNN1000 work (ICML 2021) pushes the stack to 1,000 layers. That is not a typo. The repo also includes memory-efficient modules for when your GPU starts making unhappy noises.
Key highlights
- Covers three paper implementations: DeepGCNs (ICCV 2019 / TPAMI 2021), DeeperGCN (arXiv 2020), and GNN1000 (ICML 2021)
- Task-specific examples for S3DIS, PartNet, ModelNet40, PPI, and OGB benchmarks
- Separate dense and sparse GCN libraries (
gcn_lib/densevsgcn_lib/sparse) for different data shapes - Memory-efficient GNN modules (
eff_gcn_modules) for the OGB experiments - Ablation studies across MRGCN, EdgeConv, GraphSage, and GIN architectures
Caveats
- Setup requires specific versions of PyTorch Geometric, OGB, and optionally DGL; the install script helps but version drift is a risk
- Each example task has its own README with data and pretrained model details—no unified quickstart
Verdict Worth a look if you are building deep GNNs and hitting the usual depth ceiling. Skip if you need a plug-and-play graph model; this is research code with papers attached.
Frequently asked
- What is lightaime/deep_gcns_torch?
- A research repo that borrows CNN tricks—residual connections, dilated convolutions—to make graph neural networks actually go deep.
- Is deep_gcns_torch open source?
- Yes — lightaime/deep_gcns_torch is open source, released under the MIT license.
- What language is deep_gcns_torch written in?
- lightaime/deep_gcns_torch is primarily written in Python.
- How popular is deep_gcns_torch?
- lightaime/deep_gcns_torch has 1.2k stars on GitHub.
- Where can I find deep_gcns_torch?
- lightaime/deep_gcns_torch is on GitHub at https://github.com/lightaime/deep_gcns_torch.