kyutai-labs/moshi
Full-duplex voice AI that thinks in text while talking
Moshi is a speech-text foundation model built for real-time, full-duplex conversation, using a custom streaming neural codec that compresses 24 kHz audio to 1.1 kbps.
Not currently ranked — collecting fresh signals.
star history
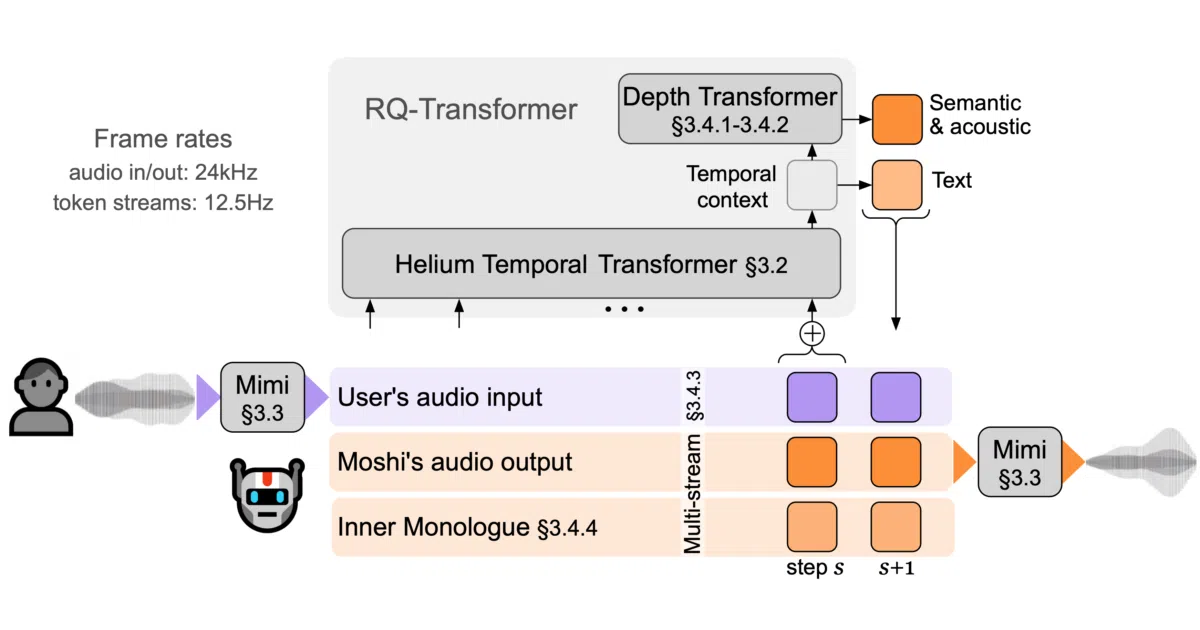
What it does Moshi is a speech-text foundation model that handles real-time, full-duplex spoken dialogue, meaning it listens and generates speech at the same time instead of taking turns. It relies on a custom streaming neural audio codec called Mimi, and the repository provides three inference backends: PyTorch for research, MLX for on-device Apple hardware, and Rust for production. The codebase also supports related Kyutai models such as Hibiki for simultaneous speech translation.
The interesting bit The model generates an “inner monologue”—text tokens representing its own speech—which the authors say greatly improves audio generation quality. Mimi compresses 24 kHz audio down to a 12.5 Hz representation at just 1.1 kbps with an 80 ms frame size, beating non-streaming codecs like SpeechTokenizer on both bitrate and latency by adding Transformers to the encoder and decoder and aligning the frame rate closer to text tokens.
Key highlights
- Full-duplex architecture models two audio streams simultaneously: one for the user and one for Moshi.
- A 7B-parameter Temporal Transformer handles long-range time dependencies, while a smaller Depth Transformer manages per-step inter-codebook dependencies.
- Theoretical latency is 160 ms, with practical end-to-end latency reported as low as 200 ms on an L4 GPU.
- Mimi is trained with only adversarial and feature-matching losses, and its first codebook is distilled to match WavLM self-supervised representations.
- Models and code are released under CC-BY 4.0, with two fine-tuned voice variants (Moshiko and Moshika) and multiple quantization options per backend.
Caveats
- The PyTorch backend currently lacks quantization support and requires a GPU with roughly 24 GB of memory.
- Windows is not officially supported, and the MLX stack is tested specifically on Apple Silicon.
- The barebones command-line clients do not perform echo cancellation or lag compensation, so the web UI is strongly recommended for actual conversations.
Verdict Researchers and developers building low-latency voice agents or exploring audio-language model architectures should start here. If you need a lightweight, turn-based speech-to-text pipeline, Moshi’s hardware requirements and full-duplex complexity are likely overkill.
Frequently asked
- What is kyutai-labs/moshi?
- Moshi is a speech-text foundation model built for real-time, full-duplex conversation, using a custom streaming neural codec that compresses 24 kHz audio to 1.1 kbps.
- Is moshi open source?
- Yes — kyutai-labs/moshi is open source, released under the Apache-2.0 license.
- What language is moshi written in?
- kyutai-labs/moshi is primarily written in Python.
- How popular is moshi?
- kyutai-labs/moshi has 10.5k stars on GitHub.
- Where can I find moshi?
- kyutai-labs/moshi is on GitHub at https://github.com/kyutai-labs/moshi.