kevinzakka/spatial-transformer-network
Teach your CNN to look at the right pixels
A drop-in TensorFlow layer that lets a network learn its own image warping, no extra labels required.
Not currently ranked — collecting fresh signals.
star history
What it does
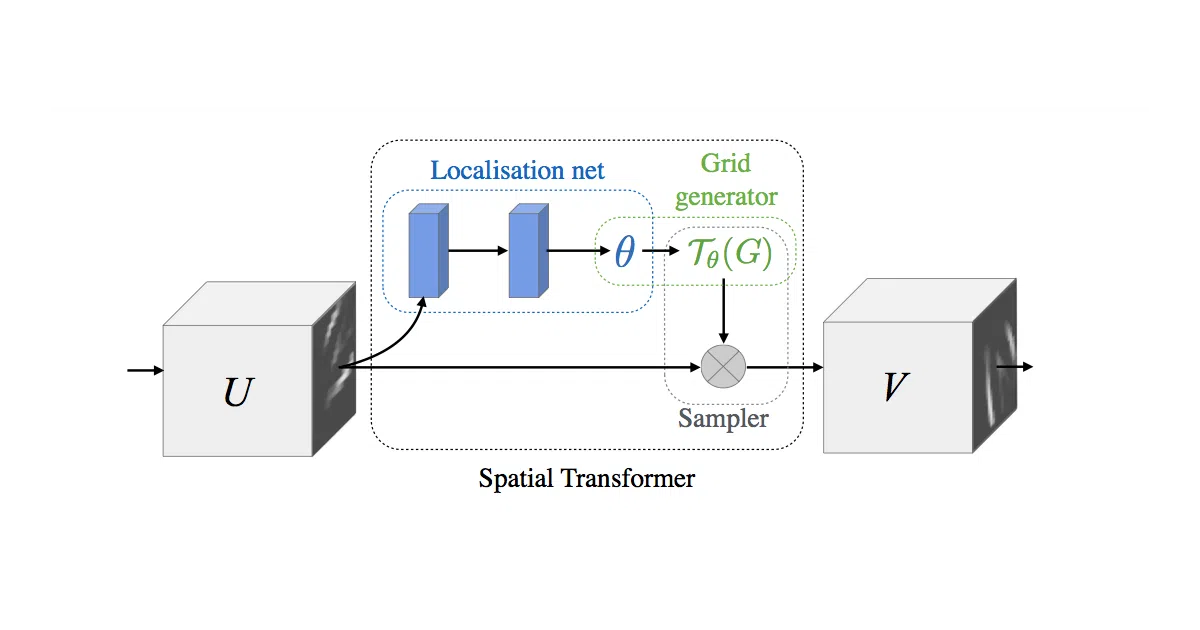
This is a clean TensorFlow implementation of Spatial Transformer Networks (STN), a differentiable module you can slot into any ConvNet. The network learns to predict an affine transformation—rotation, scaling, translation, cropping—and applies it to its own feature maps via bilinear sampling. No extra supervision, no hand-engineered data augmentation.
The interesting bit
The trick is that everything is differentiable end-to-end, including the sampling. The localization network spits out six parameters, the grid generator builds a sampling grid, and bilinear interpolation warps the input. Because gradients flow back through the sampler, the network learns where to look, not just what to see.
Key highlights
pip install stn, thenfrom stn import spatial_transformer_network as transformer— single function call- Supports arbitrary output dimensions for explicit upsampling/downsampling
- Includes a “Sanity Check” notebook with a 45° rotation example
- Author wrote a detailed two-part tutorial series explaining the math
- Identity initialization of the localization network is recommended to start training stable
Caveats
- Built for older TensorFlow (uses
tf.placeholderandtf.matmulin examples); likely needs tweaks for TF 2.x eager execution - Only affine transformations; the paper’s full STN supports more general warping
- You must build and train the localization network yourself—this repo provides the sampler, not a complete model
Verdict
Worth a look if you’re working with geometrically variable inputs in legacy TensorFlow and want learned attention without label overhead. Skip it if you’re already in PyTorch or need production-grade spatial transformers—modern frameworks have this baked in now.
Frequently asked
- What is kevinzakka/spatial-transformer-network?
- A drop-in TensorFlow layer that lets a network learn its own image warping, no extra labels required.
- Is spatial-transformer-network open source?
- Yes — kevinzakka/spatial-transformer-network is open source, released under the MIT license.
- What language is spatial-transformer-network written in?
- kevinzakka/spatial-transformer-network is primarily written in Python.
- How popular is spatial-transformer-network?
- kevinzakka/spatial-transformer-network has 1k stars on GitHub.
- Where can I find spatial-transformer-network?
- kevinzakka/spatial-transformer-network is on GitHub at https://github.com/kevinzakka/spatial-transformer-network.