kevinhughes27/TensorKart
Teaching a neural network to drive Rainbow Road
A 2017-vintage end-to-end imitation learning pipeline that watches you play Mario Kart 64, then tries not to drive off the cliff.
Not currently ranked — collecting fresh signals.
star history
What it does
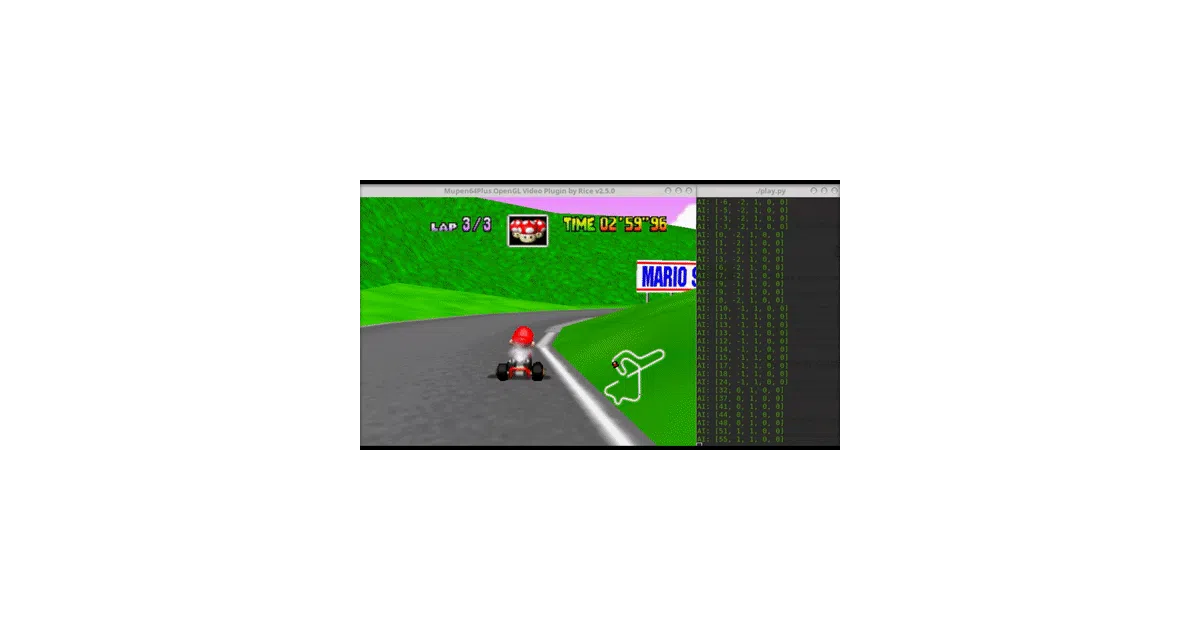
TensorKart records your joystick inputs while you race in the mupen64plus emulator, then trains a TensorFlow model to map raw screenshots directly to controller outputs. A separate play.py script feeds live emulator frames to the model and pipes the predicted commands back in via the gym-mupen64plus environment. You can grab the wheel back by holding the LB button.
The interesting bit
The whole pipeline is aggressively simple: screenshot in, joystick vector out. No track geometry, no opponent awareness, no memory of the last frame. The README notes that training on just eight races across three tracks sometimes generalizes to an unseen course (Royal Raceway), which is either impressive or a reminder that Mario Kart 64 tracks are mostly green-and-blue texture soup.
Key highlights
- End-to-end imitation learning with no hand-crafted features
- Training set is tiny: 8 races, ~1 hour GPU training with cuDNN
- Live override via LB button — the “oh no” safety switch
- Includes data viewer and CSV trim tools for cleaning up bad screenshots
- Explicitly designed as a baseline for future reinforcement learning
Caveats
- The README warns that screenshots occasionally capture your desktop instead of the emulator; you must manually scrub
data.csv - GUI freezes during recording to avoid frame drops
- Requires careful window positioning (top-left corner) for screen capture to work
- Future work section admits the reinforcement signal is currently just
-1per timestep — the AI knows it’s losing, but not why
Verdict
Grab this if you want a clean, hackable imitation-learning skeleton for retro games, or if you need to explain end-to-end autonomy to someone who only cares about Mario. Skip it if you want something that trains itself; the RL layer is still a “future work” bullet point.
Frequently asked
- What is kevinhughes27/TensorKart?
- A 2017-vintage end-to-end imitation learning pipeline that watches you play Mario Kart 64, then tries not to drive off the cliff.
- Is TensorKart open source?
- Yes — kevinhughes27/TensorKart is open source, released under the MIT license.
- What language is TensorKart written in?
- kevinhughes27/TensorKart is primarily written in Python.
- How popular is TensorKart?
- kevinhughes27/TensorKart has 1.6k stars on GitHub.
- Where can I find TensorKart?
- kevinhughes27/TensorKart is on GitHub at https://github.com/kevinhughes27/TensorKart.