kendryte/nncase
A compiler for chips you've never heard of
nncase squeezes TensorFlow Lite, ONNX, and Caffe models onto Kendryte's edge AI accelerators with static memory and zero-copy loading.
Not currently ranked — collecting fresh signals.
star history
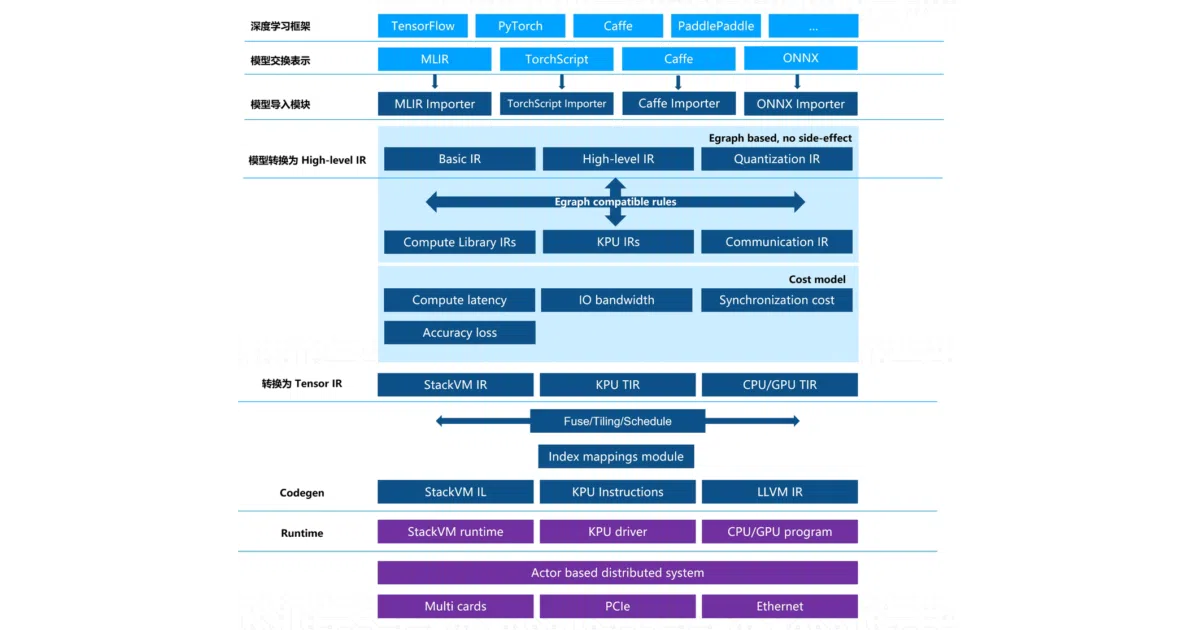
What it does
nncase is a neural network compiler that takes standard model formats (TFLite, ONNX, Caffe) and targets them to Kendryte’s family of edge AI chips: the older K210/K510 and the newer K230. It handles quantization, operator fusion, and spits out a flat binary you can load without heap allocation. Think of it as a very specialized, very opinionated backend for very cheap hardware.
The interesting bit
The K230 support is closed-source—you can only get it via pip, not by building from the repo. The README is admirably blunt about this: “At present, the source code related to k510 and K230 chips is not open source.” So the GitHub repo is effectively a partial source drop for an otherwise proprietary toolchain. The static memory allocation and zero-copy model loading are the real engineering wins for resource-starved devices.
Key highlights
- Supports TFLite, ONNX, and Caffe frontends with documented operator coverage
- Post-training quantization (uint8) with calibration datasets
- Benchmarks published for K230: MobileNetV2 at 600 FPS, YOLOv5s at ~24 FPS, YOLOv8s-pose at ~5.6 FPS
- Flat model format eliminates runtime parsing overhead
- Active enough to have a Telegram group, a QQ group, and a Bilibili channel
Caveats
- K230/K510 compiler backends are closed-source; building from source only gets you K210 support
- Windows K230 install requires manual wheel download instead of simple pip
- Some accuracy drop on YOLOv8s detection (mAP50-90: 0.446 → 0.404) and pose models
Verdict
Worth a look if you’re actually shipping on Kendryte silicon. For everyone else, it’s a useful reference for how far you can push static allocation and operator fusion on sub-dollar AI accelerators—just don’t expect to hack on the latest backend.
Frequently asked
- What is kendryte/nncase?
- nncase squeezes TensorFlow Lite, ONNX, and Caffe models onto Kendryte's edge AI accelerators with static memory and zero-copy loading.
- Is nncase open source?
- Yes — kendryte/nncase is open source, released under the Apache-2.0 license.
- What language is nncase written in?
- kendryte/nncase is primarily written in C#.
- How popular is nncase?
- kendryte/nncase has 895 stars on GitHub.
- Where can I find nncase?
- kendryte/nncase is on GitHub at https://github.com/kendryte/nncase.