kaito-project/kaito
Kubernetes operator that turns model IDs into GPU clusters
KAITO automates the tedious parts of running LLMs on Kubernetes—GPU memory estimation, node provisioning, and distributed inference configuration—behind a simplified CRD.
Not currently ranked — collecting fresh signals.
star history
What it does
KAITO is a Kubernetes operator suite that automates LLM inference, fine-tuning, and RAG engine deployment. You hand it a GPU instance type and a HuggingFace model ID; its controllers estimate memory requirements, auto-provision GPU nodes via Karpenter, and configure pipeline, tensor, and data parallelism presets based on hardware topology. It also runs a separate RAG engine operator that wires up vector databases, embedding services, and LlamaIndex orchestration behind a single CRD.
The interesting bit
The project treats distributed inference configuration as an implementation detail rather than a user concern. Instead of asking you to calculate how many A100s you need or how to shard a model, the controller derives optimal node counts and parallelism strategies from the model metadata and GPU specs, then provisions the nodes automatically. It even uses local NVMe for model storage, sidestepping the usual shared-storage dance for inference workloads.
Key highlights
- Abstracts distributed inference behind a simplified
WorkspaceCRD: provide a GPU type and HuggingFace ID, and the controller handles tensor, pipeline, and data parallelism presets. - Integrates with Karpenter-compatible node auto-provisioners to spin up GPU nodes based on its own memory estimation, rather than forcing you to pre-size clusters.
- Supports any vLLM-compatible HuggingFace model, with LoRA adapters and KVCache offloading enabled by default.
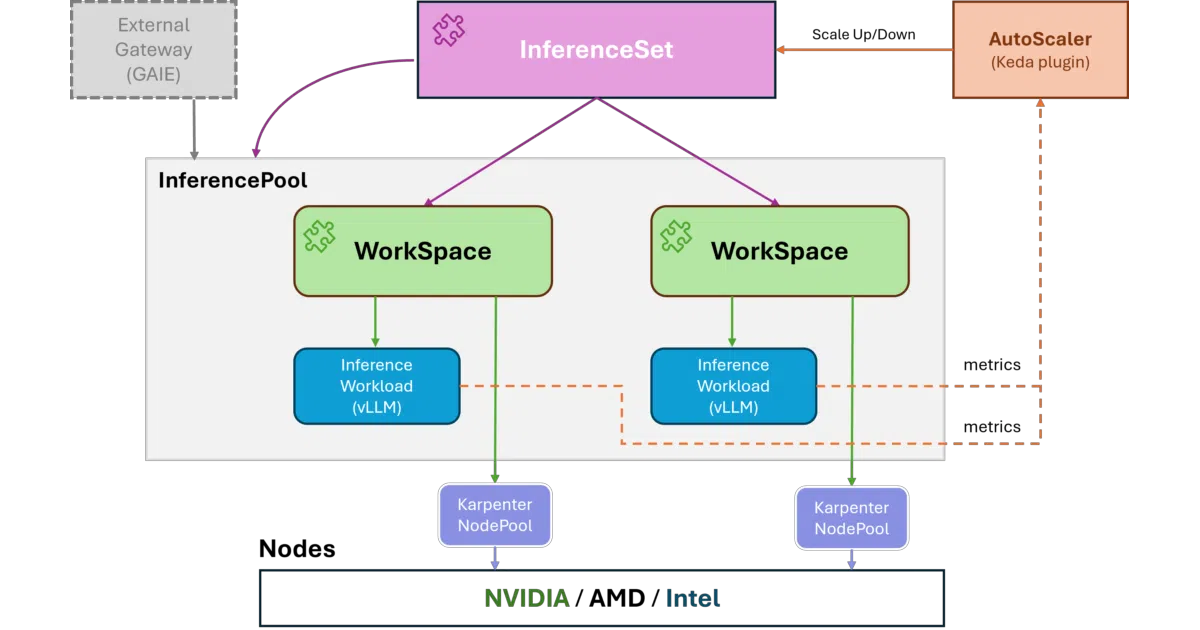
- Includes an
InferenceSetandInferencePoolCRD that integrate with KEDA and the Gateway API Inference Extension for request-based autoscaling and KVCache-aware traffic routing. - Bundles a
RAGEngineoperator that sets up hybrid search (BM25 + vector via FAISS, Qdrant, or Milvus) and LlamaIndex orchestration, including an optional built-in LLM endpoint.
Caveats
- Inference is currently vLLM-only; other serving engines are not yet supported.
- RAG service details and custom-model guides live in external documentation, not the README.
- GPU node auto-provisioning depends on a Karpenter-core-compatible provisioner (the repo tests against Microsoft’s open-source
gpu-provisioner).
Verdict
If you are a platform team tired of hand-crafting YAML to shard LLMs across GPU nodes, KAITO is worth a look. If you are not running Kubernetes or you prefer to manage inference infrastructure manually, it is not for you.
Frequently asked
- What is kaito-project/kaito?
- KAITO automates the tedious parts of running LLMs on Kubernetes—GPU memory estimation, node provisioning, and distributed inference configuration—behind a simplified CRD.
- Is kaito open source?
- Yes — kaito-project/kaito is an open-source project tracked on heatdrop.
- What language is kaito written in?
- kaito-project/kaito is primarily written in Go.
- How popular is kaito?
- kaito-project/kaito has 985 stars on GitHub.
- Where can I find kaito?
- kaito-project/kaito is on GitHub at https://github.com/kaito-project/kaito.