jrzaurin/pytorch-widedeep
Wide & Deep learning for spreadsheets that have opinions
A PyTorch toolkit that lets you bolt text, images, and tabular data into Google's Wide & Deep architecture without writing fusion boilerplate.
Not currently ranked — collecting fresh signals.
star history
What it does
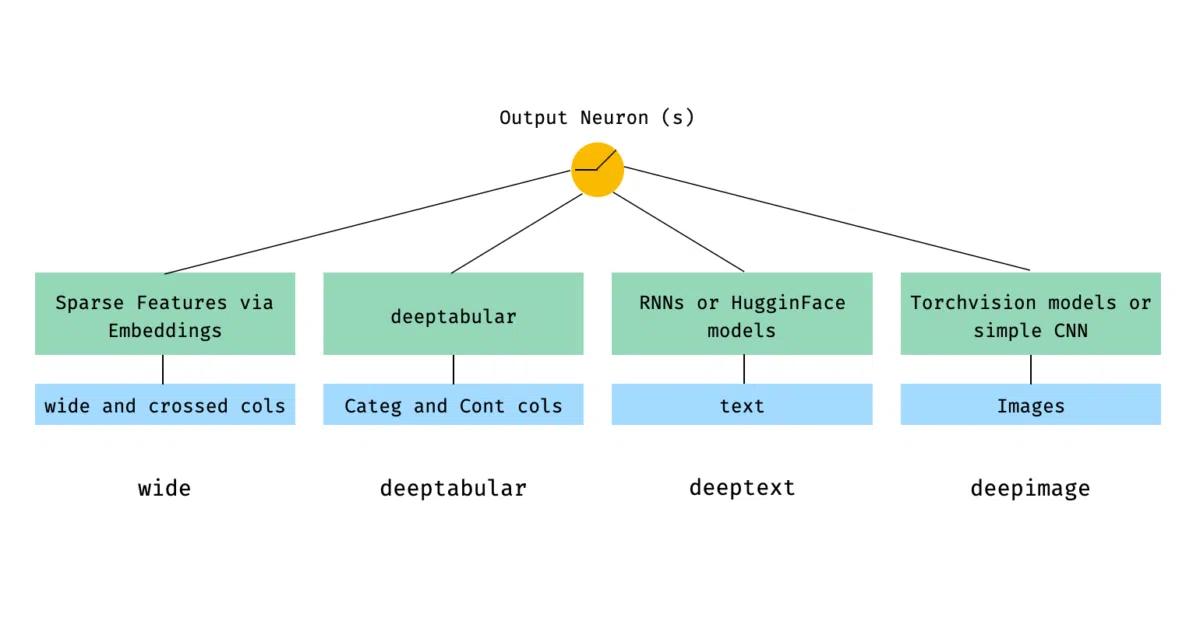
pytorch-widedeep implements Google’s Wide & Deep algorithm for multi-modal datasets. You feed it tabular data, text, images, or any combination; it preprocesses each modality and fuses them into a single model with optional fully-connected heads on top. The library handles the boring glue—preprocessors for categorical embeddings, text tokenization, image transforms—so you can mix TabMlp, TabTransformer, BasicRNN, or Hugging Face models in a few lines.
The interesting bit
The real convenience is the WideDeep container: as long as your custom model exposes an output_dim property, it slots in alongside built-in components. The README demonstrates architectures from simple wide+tabular to multi-text-column setups with shared or separate encoders, all using nearly identical code patterns.
Key highlights
- Preprocessors for tabular (categorical + continuous), text, and image modalities
- Swappable tabular back-ends:
TabMlp,TabResnet,TabNet,TabTransformer, and others - Text models include RNN variants and
HFModelfor Hugging Face transformers - Optional
head_hidden_dimsparameter stacks FC layers on top of fused representations - Custom models accepted if they implement
output_dim; examples in repo - Published in JOSS with benchmarking experiments against LightGBM (linked separately)
Caveats
- The README shows toy examples with 100 rows and random noise images; performance claims on real data are not made in the sources
- Some architecture figures in the README are referenced but not fully explained without reading the docs
Verdict
Worth a look if you’re building recommendation or ranking systems where tabular metadata, text, and images all matter. Skip it if you need pure computer vision or NLP pipelines without structured data—the tabular component is the gravitational center here.
Frequently asked
- What is jrzaurin/pytorch-widedeep?
- A PyTorch toolkit that lets you bolt text, images, and tabular data into Google's Wide & Deep architecture without writing fusion boilerplate.
- Is pytorch-widedeep open source?
- Yes — jrzaurin/pytorch-widedeep is open source, released under the Apache-2.0 license.
- What language is pytorch-widedeep written in?
- jrzaurin/pytorch-widedeep is primarily written in Python.
- How popular is pytorch-widedeep?
- jrzaurin/pytorch-widedeep has 1.4k stars on GitHub.
- Where can I find pytorch-widedeep?
- jrzaurin/pytorch-widedeep is on GitHub at https://github.com/jrzaurin/pytorch-widedeep.