jqtangust/Robust-R1
Teaching vision models to notice when the image is broken
A VLM that reasons about visual degradation instead of hallucinating through it.
Not currently ranked — collecting fresh signals.
star history
What it does
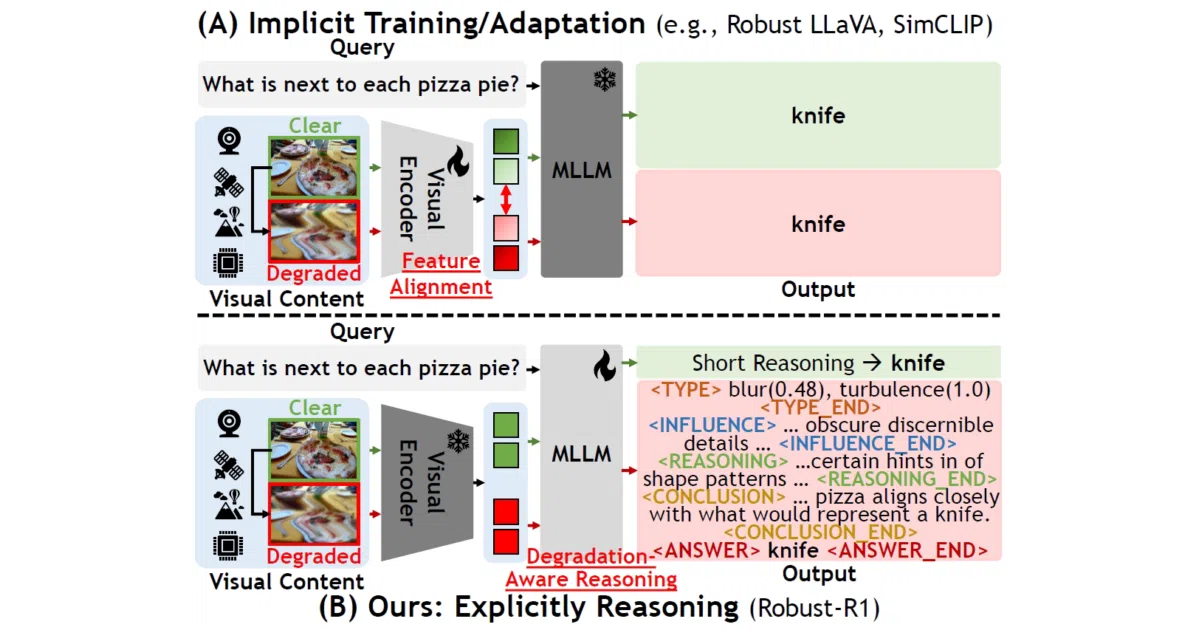
Robust-R1 is a fine-tuned vision-language model built on Qwen2.5-VL-3B that explicitly reasons about image quality before answering. It was trained on a custom dataset of degraded images and evaluated with a dedicated corruption pipeline, including the R-Bench benchmark for real-world distortions. The project ships two checkpoints: one from supervised fine-tuning and a second refined with reinforcement learning.
The interesting bit
Most VLMs treat a blurry or noisy image as someone else’s problem. Robust-R1 tries to make degradation awareness part of the reasoning chain itself, not just a preprocessing hack. The authors frame this as fixing “isolated optimization” between the visual encoder and the language model — essentially, the vision side and the text side finally comparing notes on whether the input is trustworthy.
Key highlights
- Two-stage training: SFT via LLaMA-Factory, then RL with a GRPO script
- Custom degradation pipeline generates three intensity levels for stress-testing
- Evaluation integrates with VLMEvalKit and the R-Bench real-world corruption benchmark
- Live HuggingFace demo available; CLI and local GUI options provided
- AAAI 2026 Oral, which at least suggests reviewers found the problem worth solving
Caveats
- The README is heavy on setup steps and light on actual accuracy numbers or comparisons to baseline Qwen2.5-VL
- “Degradation-aware reasoning” is the pitch, but the sources don’t clarify how explicitly the model verbalizes corruption versus simply coping with it internally
Verdict
Worth a look if you’re building VLMs for photography, surveillance, or any domain where image quality isn’t guaranteed. Skip it if you need a fully general-purpose vision model — this is a specialized robustness play, not a capability upgrade across the board.
Frequently asked
- What is jqtangust/Robust-R1?
- A VLM that reasons about visual degradation instead of hallucinating through it.
- Is Robust-R1 open source?
- Yes — jqtangust/Robust-R1 is an open-source project tracked on heatdrop.
- What language is Robust-R1 written in?
- jqtangust/Robust-R1 is primarily written in Python.
- How popular is Robust-R1?
- jqtangust/Robust-R1 has 530 stars on GitHub.
- Where can I find Robust-R1?
- jqtangust/Robust-R1 is on GitHub at https://github.com/jqtangust/Robust-R1.