jina-ai/reader
Turn any URL into LLM-friendly text with a prefix
Reader converts URLs and search queries into clean, LLM-friendly markdown so your agents don't have to parse HTML themselves.
Velocity · 7d
+24
★ / day
Trend
↗accelerating
star history
What it does
Reader is an open-source extraction engine that fetches web pages, PDFs, Microsoft Office files, and images, then distills them into markdown or plain text. It exposes two main endpoints: r.jina.ai for single URLs and s.jina.ai for web search, which automatically retrieves and cleans the top five results. Images get passed through a vision-language model for captioning, so even text-only downstream LLMs receive useful context.
The interesting bit
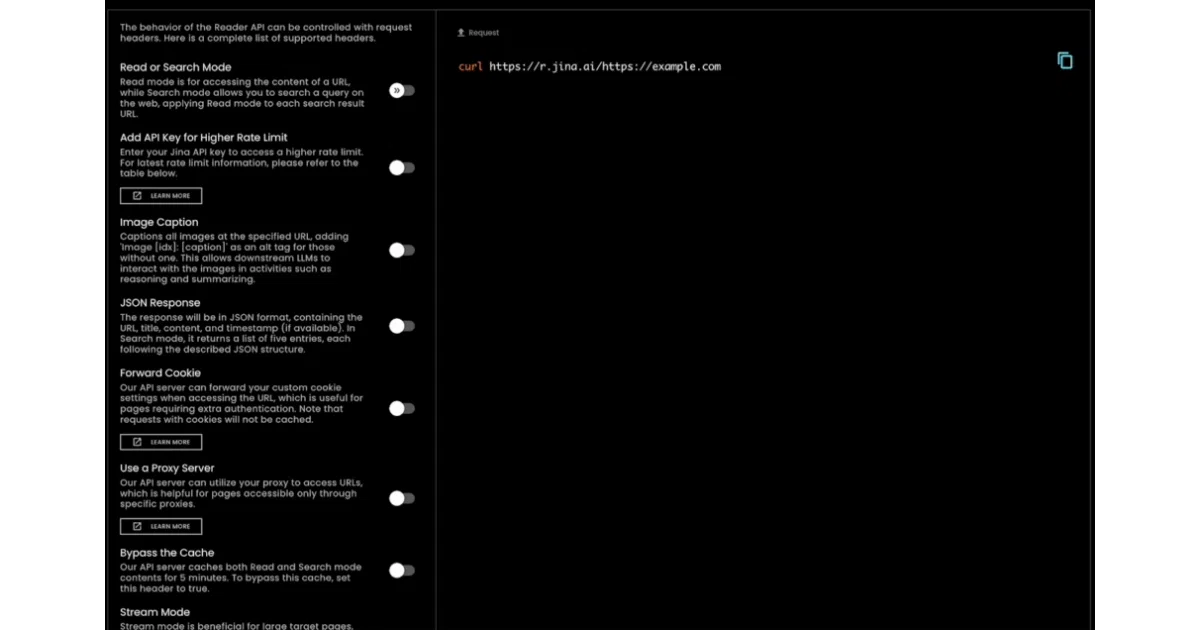
The entire interface is just a URL prefix, meaning any HTTP client can call it without SDKs or auth headers. Under the hood it intelligently picks between headless Chrome and a lightweight curl-impersonate fetch, and offers unusually fine-grained request headers—token budgets, CSS selectors, and six levels of response timing—to let you trade latency for completeness.
Key highlights
- Prepend
r.jina.aito any URL to receive markdown, HTML, text, screenshots, or semantically chunked output - Search via
s.jina.aireturns full content from the top five results rather than search-engine snippets alone - Handles PDFs, Word, Excel, PowerPoint, and image captioning for text-only downstream models
- Deep controls via headers include
x-max-tokens,x-target-selector,x-respond-timing, and markdown chunking strategies - Open-source branch runs stateless by default with optional MinIO or S3-compatible bucket caching for self-hosted deployments
Caveats
- The open-source branch strips the MongoDB-backed SaaS storage layer, so it runs stateless (or with optional bucket caching) by default
Verdict
Teams building RAG pipelines or agents that ingest live web content will save a lot of scraping headaches. If you already run your own headless-browser farm and don’t need another upstream dependency, this won’t change your life.
Frequently asked
- What is jina-ai/reader?
- Reader converts URLs and search queries into clean, LLM-friendly markdown so your agents don't have to parse HTML themselves.
- Is reader open source?
- Yes — jina-ai/reader is open source, released under the Apache-2.0 license.
- What language is reader written in?
- jina-ai/reader is primarily written in TypeScript.
- How popular is reader?
- jina-ai/reader has 11.7k stars on GitHub and is currently accelerating.
- Where can I find reader?
- jina-ai/reader is on GitHub at https://github.com/jina-ai/reader.