jeonsworld/ViT-pytorch
Porting Google's image transformer to PyTorch, patch by patch
This repo converts Google's official Vision Transformer checkpoints to PyTorch and proves the accuracy still holds on standard image benchmarks.
Not currently ranked — collecting fresh signals.
star history
What it does
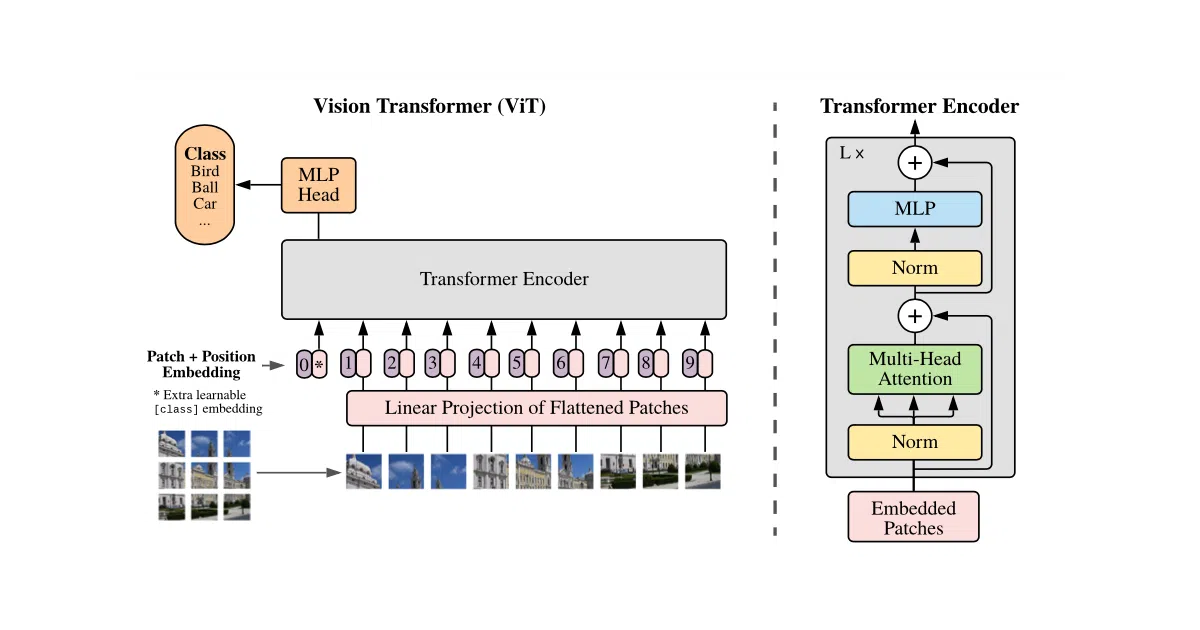
This is a straightforward PyTorch translation of Google’s Vision Transformer (ViT). It takes the original architecture and pretrained weights—from the 86-million-parameter base model up to the 631-million-parameter giant—and makes them runnable in PyTorch. The repo focuses on verifying fidelity: the authors train on CIFAR-10 and CIFAR-100 and report accuracy numbers side-by-side with the official Google results to show the conversion did not break anything.
The interesting bit
The value is not novelty but diligence. At a time when many PyTorch versions of popular models drift from the originals, this repo treats the official checkpoints as the ground truth and measures itself against them. It also includes a Jupyter notebook to visualize the self-attention maps, turning the model’s black-box patch interactions into something you can actually see.
Key highlights
- Loads Google’s official
.npzcheckpoints for models trained on ImageNet-21k and fine-tuned on ImageNet-2012. - Supports hybrid ResNet-50 + Transformer variants alongside pure ViT models.
- Includes mixed-precision training support and gradient accumulation for smaller GPUs.
- Provides an attention-map visualization notebook to inspect where the model looks.
- Published TensorBoard logs and training times for direct comparison with upstream results.
Caveats
- Only CIFAR-10 and CIFAR-100 are built-in; other datasets require editing
data_utils.py. - The ViT-H/14 result is marked “WIP” in the benchmark table.
- The README contains minor typos and rough phrasing (“This paper show”, “author use”), which hints at limited maintenance polish.
Verdict
Grab this if you specifically need Google’s original ViT weights in a clean PyTorch training loop and want evidence that the port is faithful. If you just need a general-purpose vision transformer, timm—which the repo itself references—is likely the smoother path.
Frequently asked
- What is jeonsworld/ViT-pytorch?
- This repo converts Google's official Vision Transformer checkpoints to PyTorch and proves the accuracy still holds on standard image benchmarks.
- Is ViT-pytorch open source?
- Yes — jeonsworld/ViT-pytorch is open source, released under the MIT license.
- What language is ViT-pytorch written in?
- jeonsworld/ViT-pytorch is primarily written in Jupyter Notebook.
- How popular is ViT-pytorch?
- jeonsworld/ViT-pytorch has 2.2k stars on GitHub.
- Where can I find ViT-pytorch?
- jeonsworld/ViT-pytorch is on GitHub at https://github.com/jeonsworld/ViT-pytorch.