jackroos/VL-BERT
BERT grows eyes: pre-training that actually looks at the picture
A 2020 ICLR paper that extends BERT to process both text and visual features in a single transformer, with working PyTorch code for VQA, visual reasoning, and referring expression tasks.
Not currently ranked — collecting fresh signals.
star history
What it does
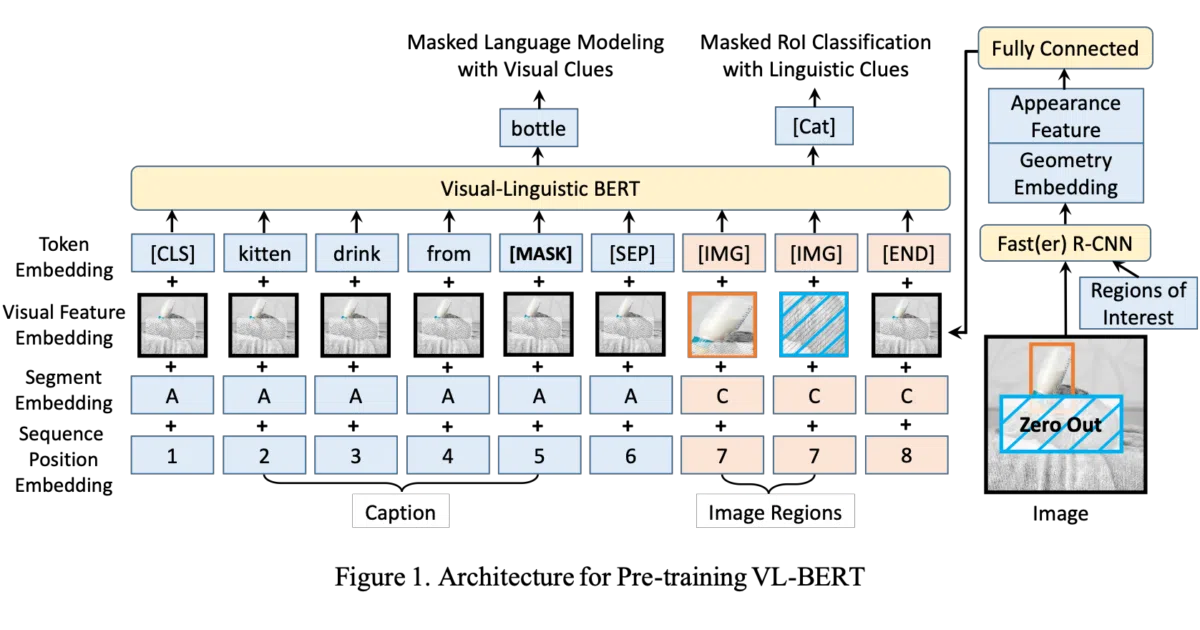
VL-BERT feeds text and visual region features into a standard BERT-style transformer, pre-training on image captions and plain text so the model learns generic cross-modal representations. It then fine-tunes on downstream tasks like Visual Commonsense Reasoning, VQA, and RefCOCO+ phrase grounding. The codebase wraps this in distributed PyTorch training with FP16, gradient accumulation, and TensorBoard logging.
The interesting bit
The “simple yet powerful” pitch is honest: this is essentially BERT with visual tokens appended, not a bespoke fusion architecture. The authors bet that BERT’s existing self-attention would learn cross-modal relationships if you just gave it the right inputs. The attention visualization (added in a 2020 update) lets you watch the model attend to image regions while reading text.
Key highlights
- Single-stream transformer: text and visual features share one self-attention stack, no separate encoders to fuse
- Pre-trained on Conceptual Captions plus BooksCorpus/Wikipedia for both visual-linguistic and pure language signal
- Ready-to-run configs for three tasks: VCR (Q→A and QA→R), VQA, and RefCOCO+ referring expression comprehension
- Distributed single/multi-machine training scripts included, with a documented deadlock workaround for RefCOCO+ on PyTorch dataloaders
- Builds on a stack of familiar tools: transformers, maskrcnn-benchmark, mmdetection, bottom-up-attention features
Caveats
- Environment is pinned to PyTorch 1.0/1.1 and CUDA 9.0 — decidedly 2019 vintage, expect dependency archaeology
- Requires pre-extracted bottom-up-attention visual features; end-to-end image training isn’t the default path
- The “simple” framing undersells how much scaffolding this borrows: deformable convolutions, multiple detection frameworks, and AllenNLP pieces all appear in the acknowledgements
Verdict
Worth studying if you’re tracing how vision-language pre-training evolved from two-stream fusion (ViLBERT) toward unified architectures that look more like today’s multimodal LLMs. Skip if you need something that runs on modern PyTorch without a conda time machine.
Frequently asked
- What is jackroos/VL-BERT?
- A 2020 ICLR paper that extends BERT to process both text and visual features in a single transformer, with working PyTorch code for VQA, visual reasoning, and referring expression tasks.
- Is VL-BERT open source?
- Yes — jackroos/VL-BERT is open source, released under the MIT license.
- What language is VL-BERT written in?
- jackroos/VL-BERT is primarily written in Jupyter Notebook.
- How popular is VL-BERT?
- jackroos/VL-BERT has 742 stars on GitHub.
- Where can I find VL-BERT?
- jackroos/VL-BERT is on GitHub at https://github.com/jackroos/VL-BERT.