iver56/torch-audiomentations
GPU-native audio augmentation that stays in PyTorch
Because copying tensors to CPU for data augmentation is a bottleneck nobody asked for.
Not currently ranked — collecting fresh signals.
star history
What it does
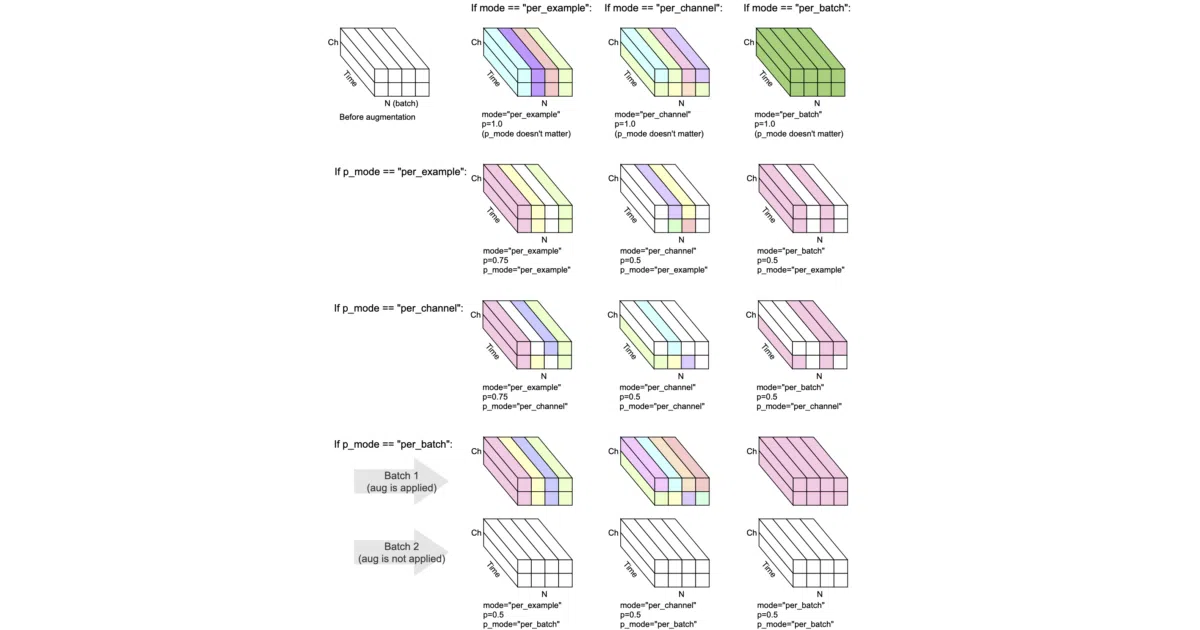
torch-audiomentations is a collection of audio transforms—gain, filtering, pitch shift, noise injection, impulse response convolution—that operate directly on PyTorch tensors. They subclass nn.Module, so you can drop them into a model or training pipeline without leaving the GPU. The library supports batched multichannel audio and offers three randomization modes: per-batch, per-example, or per-channel.
The interesting bit
The “mode” parameter is the quietly clever part. It lets you control whether an augmentation applies identically across a batch, varies per sample, or even per stereo channel—useful for fighting positional bias or simulating realistic recording conditions without hand-rolling tensor indexing.
Key highlights
- Most transforms are differentiable, so they can live inside the forward pass if needed
- GPU speedups exist but vary by transform; the README is honest that not everything beats CPU
- 15+ waveform transforms including
TimeInversion(reverse audio like a random image flip) andShuffleChannels - Compose API with
OneOf/SomeOffor stochastic transform selection - Recently dropped
librosadependency in favor oftorchaudio
Caveats
- Target data processing (e.g., augmenting labels alongside inputs) is experimental with a workaround involving
freeze_parameters - Multiprocessing can leak memory; CPU transforms are the suggested workaround
- Multi-GPU / DDP is not officially supported—the author is literally asking for hardware donations to test it
PitchShiftstruggles with small shifts at low sample rates
Verdict
Worth a look if you’re training audio models in PyTorch and tired of CPU-GPU ping-pong during data loading. Skip it if you need mature multi-GPU support or heavy spectral-domain augmentation; this is waveform-only and still early-stage.
Frequently asked
- What is iver56/torch-audiomentations?
- Because copying tensors to CPU for data augmentation is a bottleneck nobody asked for.
- Is torch-audiomentations open source?
- Yes — iver56/torch-audiomentations is open source, released under the MIT license.
- What language is torch-audiomentations written in?
- iver56/torch-audiomentations is primarily written in Python.
- How popular is torch-audiomentations?
- iver56/torch-audiomentations has 1.2k stars on GitHub.
- Where can I find torch-audiomentations?
- iver56/torch-audiomentations is on GitHub at https://github.com/iver56/torch-audiomentations.