infiniflow/ragflow
RAGFlow: An Agentic RAG That Actually Cites Its Sources
RAGFlow fuses deep document parsing with agentic workflows so LLMs can answer from messy corporate documents without making things up.
Velocity · 7d
+81
★ / day
Trend
↗accelerating
star history
What it does
RAGFlow is an open-source engine that runs retrieval-augmented generation pipelines with an agentic twist. It ingests documents from sources like Confluence, Notion, S3, and Google Drive, parses them with a dedicated deep-document understanding module, and serves grounded answers to LLMs with traceable citations. You can self-host the entire stack or use the managed cloud offering.
The interesting bit
Most RAG tools treat parsing as a black box; RAGFlow exposes it. The project offers template-based, explainable chunking with a visual interface so humans can audit exactly what context is fed to the model. It also layers in agentic workflows, memory, MCP support, and a sandboxed code executor, turning a static search pipeline into an autonomous research assistant that can iterate on its own retrieval strategy.
Key highlights
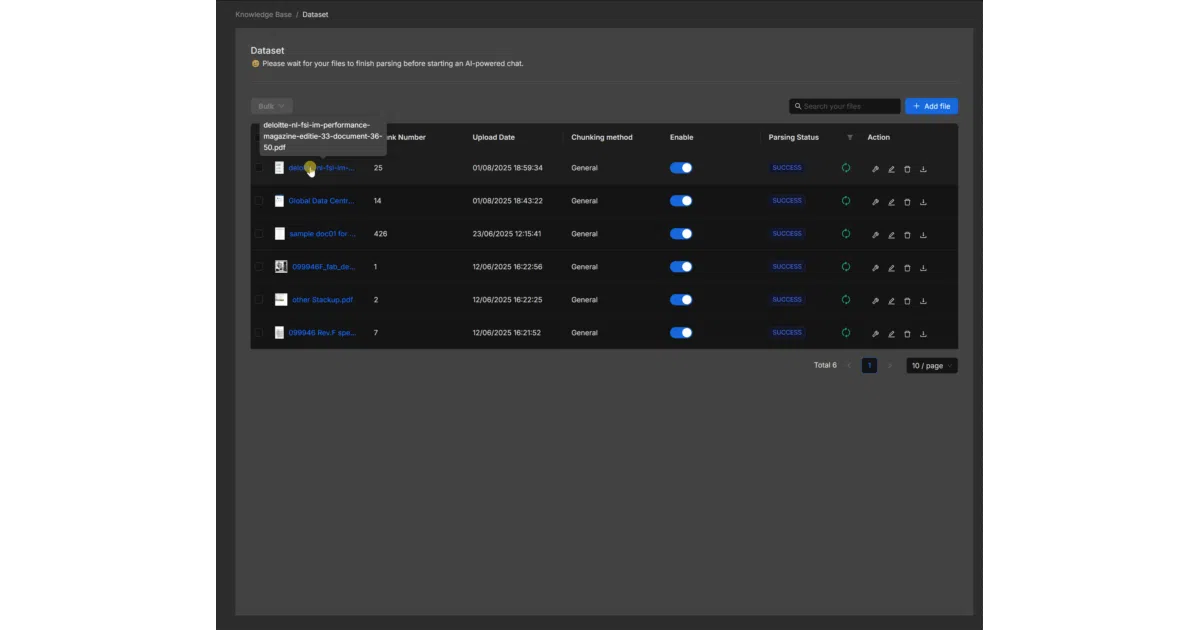
- Deep document parsing for complex unstructured formats—Word, slides, scans, images—using template-based chunking that humans can inspect and adjust.
- Grounded answers with traceable citations and chunk visualization, explicitly designed to reduce hallucinations.
- Agentic workflows with memory, MCP support, and a sandboxed Python/JavaScript code executor for autonomous task handling.
- Broad data source support including Confluence, S3, Notion, Discord, Google Drive, and web pages.
- Configurable LLMs and embedding models with multiple recall and fused re-ranking.
Caveats
- Pre-built Docker images are x86-only; ARM64 users must build their own.
- The sandboxed code executor requires gVisor, adding a non-trivial infrastructure dependency.
- Minimum specs are hefty: 4 CPU cores, 16 GB RAM, and 50 GB disk.
Verdict
Organizations drowning in heterogeneous documents and needing auditable, cited LLM answers will find RAGFlow’s agentic depth worth the hardware. If you just need a lightweight vector search over a handful of clean PDFs, look elsewhere.
Frequently asked
- What is infiniflow/ragflow?
- RAGFlow fuses deep document parsing with agentic workflows so LLMs can answer from messy corporate documents without making things up.
- Is ragflow open source?
- Yes — infiniflow/ragflow is open source, released under the Apache-2.0 license.
- What language is ragflow written in?
- infiniflow/ragflow is primarily written in Go.
- How popular is ragflow?
- infiniflow/ragflow has 85.7k stars on GitHub and is currently accelerating.
- Where can I find ragflow?
- infiniflow/ragflow is on GitHub at https://github.com/infiniflow/ragflow.