ikostrikov/pytorch-a3c
The author recommends you skip this repo
A clean PyTorch A3C implementation whose own creator suggests using A2C or PPO instead.
Not currently ranked — collecting fresh signals.
star history
What it does
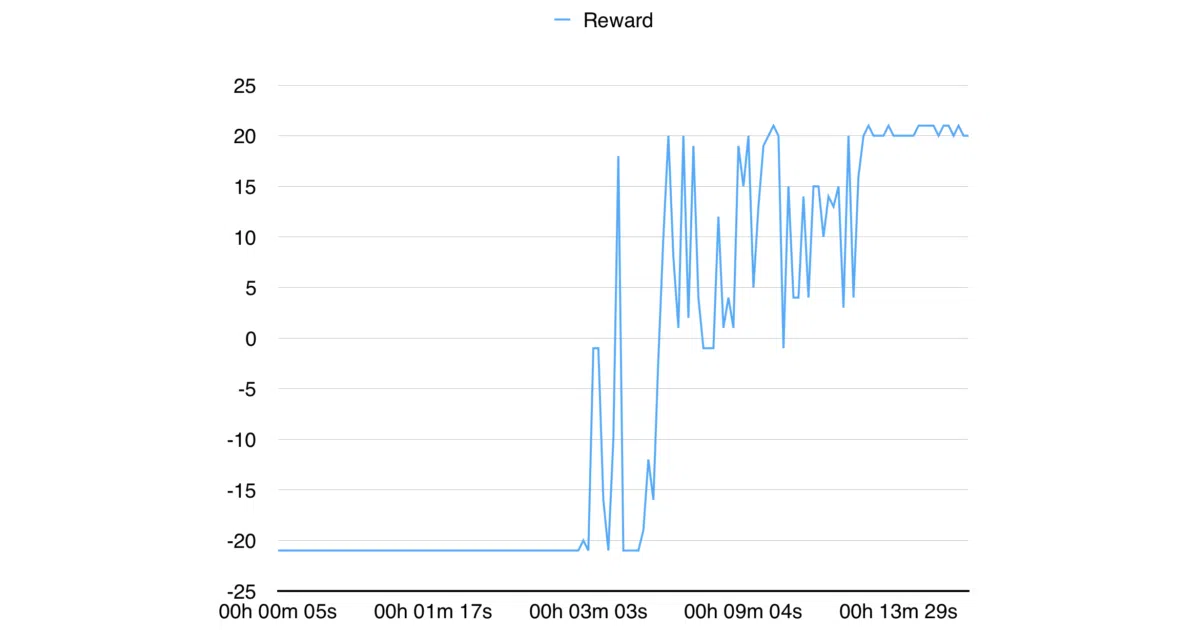
Implements Asynchronous Advantage Actor-Critic (A3C), the 2016 DeepMind algorithm that trains reinforcement-learning agents across multiple parallel processes without a GPU. You get 16 workers bashing Pong simultaneously, sharing gradient statistics through a single optimizer.
The interesting bit
The author is refreshingly honest: A2C works better, ACKTR beats both, and PPO dominates continuous control. This repo exists mainly for historical completeness and paper reproduction — a rarity in a field where everyone pretends their fork is state-of-the-art.
Key highlights
- Python 3 only; 16 processes converge Pong in ~15 minutes
- Uses shared-statistics optimizer per the original paper (not the OpenAI starter agent approach)
- Evaluation runs in a separate thread alongside training workers
- Breakout takes “more than several hours” — the README doesn’t sugarcoat it
- Author actively redirects users to his newer pytorch-a2c-ppo-acktr repo
Caveats
- No GPU support mentioned; this is CPU-multiprocessing territory
- Sparse documentation beyond basic usage and one benchmark curve
- Breakout performance is vague (“more than several hours”)
Verdict
Grab this if you need a readable A3C baseline for a course, paper comparison, or masochism. Everyone else should follow the author’s own advice and head to his A2C/PPO/ACKTR repo instead.
Frequently asked
- What is ikostrikov/pytorch-a3c?
- A clean PyTorch A3C implementation whose own creator suggests using A2C or PPO instead.
- Is pytorch-a3c open source?
- Yes — ikostrikov/pytorch-a3c is open source, released under the MIT license.
- What language is pytorch-a3c written in?
- ikostrikov/pytorch-a3c is primarily written in Python.
- How popular is pytorch-a3c?
- ikostrikov/pytorch-a3c has 1.3k stars on GitHub.
- Where can I find pytorch-a3c?
- ikostrikov/pytorch-a3c is on GitHub at https://github.com/ikostrikov/pytorch-a3c.