icoxfog417/awesome-text-summarization
A field guide to shrinking text without losing the plot
A curated map of extractive, abstractive, and hybrid approaches to automatic text summarization, with papers, datasets, and code pointers.
Not currently ranked — collecting fresh signals.
star history
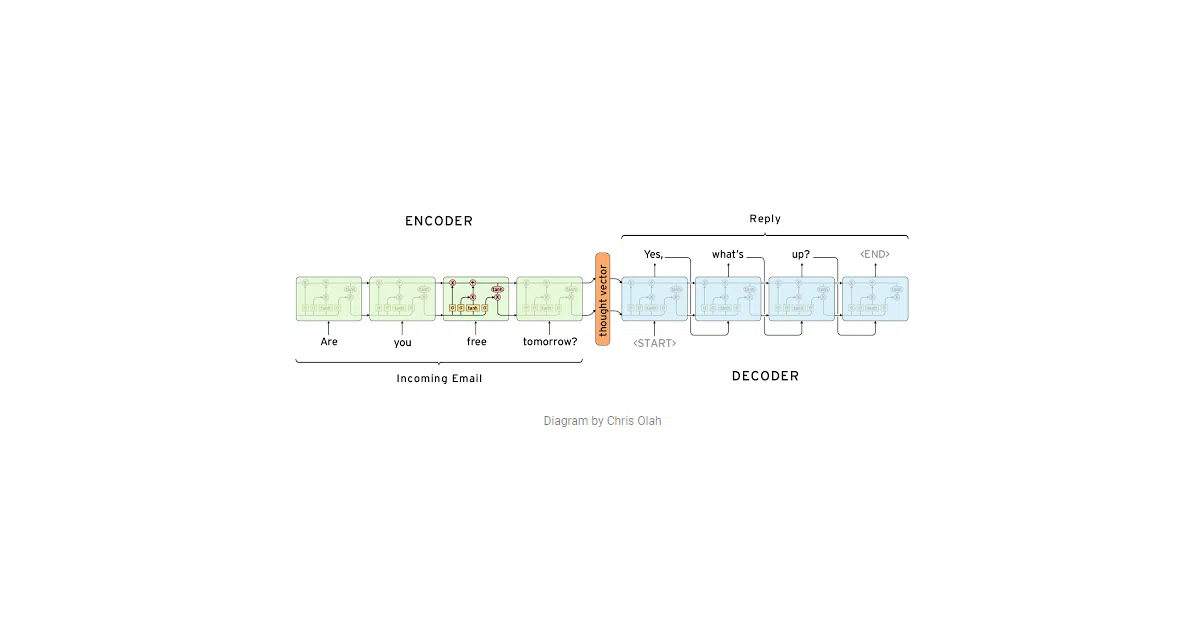
What it does This repository is a curated survey of text summarization methods, organized as a readable guide rather than a code library. It walks through how to turn documents into shorter documents — from simple “copy-and-paste” extractive techniques to neural encoder-decoder models that generate fresh sentences. The README covers task definitions (single vs. multi-document, query-focused, update summarization), evaluation approaches, and links to datasets, libraries, and key papers.
The interesting bit The guide treats summarization as a spectrum of trade-offs, not a solved problem. It explicitly notes that extractive methods are robust but inflexible, while abstractive methods can paraphrase but struggle with coherence and rare words. The encoder-decoder section even lists open problems — handling long documents, large vocabularies, and focus — that still define the research frontier.
Key highlights
- Covers five extractive families: graph-based (TextRank, LexRank), feature-based (position, verb presence, coreference counts), topic-based (LSA/SVD), grammar-based (quasi-synchronous grammar), and neural (SummaRuNNer, Bi-LSTM encoders)
- Abstractive section traces the lineage from early machine-translation approaches to modern encoder-decoder and attention models
- Links to concrete implementations: gensim, pytextrank, TextTeaser/PyTeaser, TensorFlow’s summarization tutorial
- Includes discussion of Sparck Jones’s argument that generic summarization is “wrong-headed” without purpose-specific context
- Curated resources section with datasets, libraries, articles, and papers
Caveats
- No original code or benchmarks; this is purely a reading list and conceptual guide
- Some linked papers and tools date to 2016–2018, so the neural architecture landscape (transformers, LLMs) is underrepresented
- README is truncated in the source, so later sections on transfer learning and evaluation are incomplete
Verdict Worth bookmarking if you’re entering summarization research and need a structured map of the fundamentals. Skip it if you want ready-to-run code or coverage of modern large-language-model approaches — this predates the transformer era.
Frequently asked
- What is icoxfog417/awesome-text-summarization?
- A curated map of extractive, abstractive, and hybrid approaches to automatic text summarization, with papers, datasets, and code pointers.
- Is awesome-text-summarization open source?
- Yes — icoxfog417/awesome-text-summarization is open source, released under the MIT license.
- How popular is awesome-text-summarization?
- icoxfog417/awesome-text-summarization has 1.3k stars on GitHub.
- Where can I find awesome-text-summarization?
- icoxfog417/awesome-text-summarization is on GitHub at https://github.com/icoxfog417/awesome-text-summarization.