huggingface/pytorch-openai-transformer-lm
Porting OpenAI's GPT-1 to PyTorch, weights and all
A faithful translation of the original TensorFlow transformer with a working weight importer, because not everyone speaks TF.
Not currently ranked — collecting fresh signals.
star history
What it does
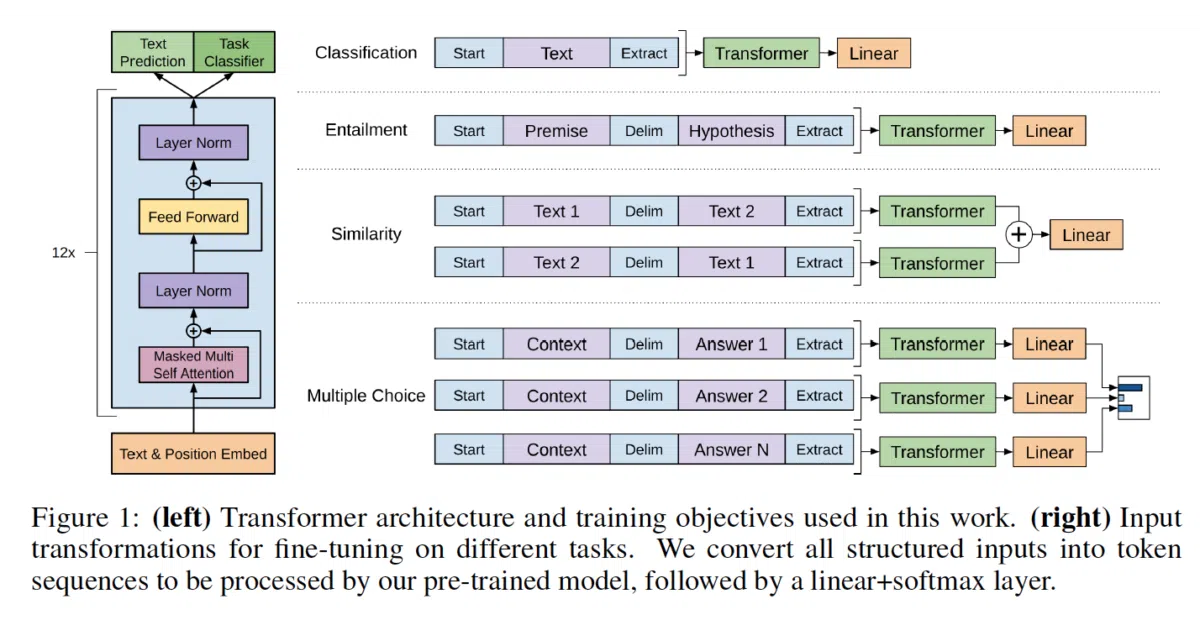
This repo re-implements OpenAI’s original 2018 “Generative Pre-Training” transformer in PyTorch, including a script that slurps the official TensorFlow pretrained weights into PyTorch tensors. You get the language model backbone, a tied LM head for generation, and a classification head for fine-tuning — all with module names matching the original TF variables to keep diffs minimal.
The interesting bit
The fidelity is almost archaeological: they even reproduced OpenAI’s custom Adam optimizer with fixed weight decay and transformer learning-rate scheduling. The ROCStories benchmark comes within 0.04% of the TensorFlow median (85.84% vs. 85.8%), which is either impressive dedication or a very expensive way to avoid installing TensorFlow.
Key highlights
- Imports OpenAI’s released pretrained weights directly; no retraining from scratch
- Single-GPU fine-tuning hits 85.84% on ROCStories in 10 minutes on a K80
- Includes
LMHeadandClfHeadclasses for language modeling or classification tasks - Custom Adam with Loshchilov-style weight decay and scheduled LR baked in
- Requires only PyTorch ≥0.4 for inference; extra deps (spacy, sklearn, etc.) only for training
Caveats
- Single-GPU only; batch size capped at 20 on a K80 vs. 64 in the official 8-GPU setup, and accuracy improves noticeably with more batch
- You must manually clone OpenAI’s repo and drop the
modelfolder in place; no automated weight download - The README’s “first experiments” note suggests multi-GPU is “not tried yet,” so scaling is DIY
Verdict
Worth a look if you need GPT-1 in PyTorch for historical reproduction or ablation work. Skip it if you want modern scale — this is the 2018 ancestor, not a maintained foundation model.
Frequently asked
- What is huggingface/pytorch-openai-transformer-lm?
- A faithful translation of the original TensorFlow transformer with a working weight importer, because not everyone speaks TF.
- Is pytorch-openai-transformer-lm open source?
- Yes — huggingface/pytorch-openai-transformer-lm is open source, released under the MIT license.
- What language is pytorch-openai-transformer-lm written in?
- huggingface/pytorch-openai-transformer-lm is primarily written in Python.
- How popular is pytorch-openai-transformer-lm?
- huggingface/pytorch-openai-transformer-lm has 1.5k stars on GitHub.
- Where can I find pytorch-openai-transformer-lm?
- huggingface/pytorch-openai-transformer-lm is on GitHub at https://github.com/huggingface/pytorch-openai-transformer-lm.