hpcaitech/ColossalAI
A distributed training framework that wants you to forget you're distributed
Colossal-AI wraps PyTorch's parallel nightmares in a config file so you can train 70B models without rewriting your laptop code.
Not currently ranked — collecting fresh signals.
star history
What it does
Colossal-AI is a PyTorch toolkit for distributed training and inference of large models. It bundles data, pipeline, tensor (1D through 3D), sequence, and ZeRO parallelism behind a configuration-driven API. The pitch: write model code like it’s single-GPU, then scale out by editing a config file rather than rewriting communication logic.
The interesting bit
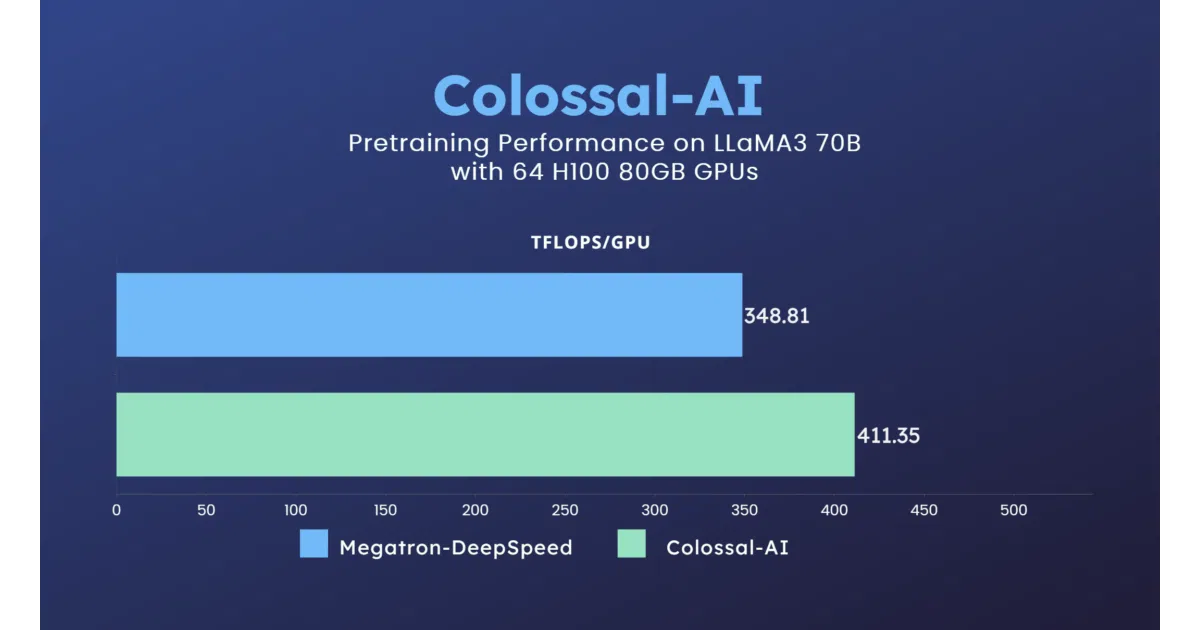
The “auto-parallelism” feature and heterogeneous memory management (via PatrickStar) suggest the project is trying to solve the actual tedious part of distributed training: not just splitting layers, but deciding how to split them and offloading to CPU/NVMe when GPU memory runs dry. The README also ships concrete benchmarks on H200 and B200 clusters—actual throughput numbers for 7B and 70B Llama-like models, not just hand-waving.
Key highlights
- Supports 1D/2D/2.5D/3D tensor parallelism, pipeline parallelism, sequence parallelism, and ZeRO—mixable via config
- Includes inference acceleration (Colossal-Inference, SwiftInfer) and single-GPU demos for GPT-2 and PaLM
- Real-world applications bundled: Open-Sora video generation, ColossalChat RLHF pipeline, AlphaFold/FastFold acceleration
- Benchmarks claim 50–70% higher throughput on B200 vs H200 for tested configurations
- Backed by HPC-AI Tech, which also operates a GPU cloud and API service—there’s commercial infrastructure behind the open-source project
Caveats
- The README is heavily interleaved with promotions for HPC-AI Cloud rentals and Model APIs; documentation density varies
- “Just a single line of code” claims (e.g., for FP8 mixed precision) appear in blog titles but aren’t demonstrated in the README itself
- Auto-parallelism details are sparse; it’s unclear how much manual tuning the config file still requires
Verdict
Worth evaluating if you’re already in PyTorch and need to scale beyond DeepSpeed or FSDP, especially for multi-modal or video workloads. Skip if you’re on JAX/MLX or want a framework without a cloud vendor attached.
Frequently asked
- What is hpcaitech/ColossalAI?
- Colossal-AI wraps PyTorch's parallel nightmares in a config file so you can train 70B models without rewriting your laptop code.
- Is ColossalAI open source?
- Yes — hpcaitech/ColossalAI is open source, released under the Apache-2.0 license.
- What language is ColossalAI written in?
- hpcaitech/ColossalAI is primarily written in Python.
- How popular is ColossalAI?
- hpcaitech/ColossalAI has 41.4k stars on GitHub.
- Where can I find ColossalAI?
- hpcaitech/ColossalAI is on GitHub at https://github.com/hpcaitech/ColossalAI.