hi-abhi/tensorflow-value-iteration-networks
Reinforcement learning with a built-in planner
A TensorFlow port of NIPS 2016's Best Paper, embedding value iteration directly inside a neural network for grid-world navigation.
Not currently ranked — collecting fresh signals.
star history
What it does
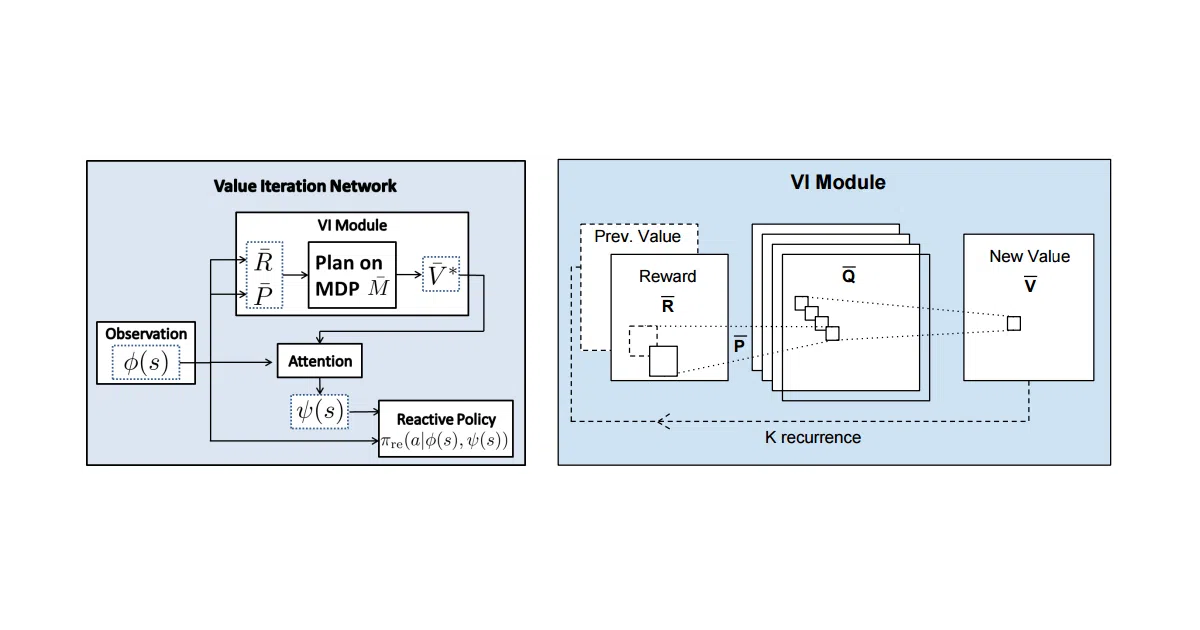
Implements Value Iteration Networks (VIN), a neural architecture that learns to plan by running an approximate value-iteration algorithm as a differentiable layer. The repo trains on GridWorld mazes (8×8 bundled, 16×16 and 28×28 downloadable) where the network must navigate from start to goal while avoiding obstacles.
The interesting bit
Instead of learning a policy from raw pixels, the network learns the reward map and transition model, then performs value iteration internally—so it generalizes to unseen maze layouts better than standard reactive policies. Think of it as giving a CNN a built-in A* module that it learns to tune.
Key highlights
- Reproduces the NIPS 2016 Best Paper results in TensorFlow (ported from Theano)
- 8×8 GridWorld converges in <30 epochs at ~98.5% accuracy (paper claims 99.6%, achievable in original Theano code)
- TensorBoard logging supported via
config.log - Includes bundled 8×8 dataset; larger datasets pulled from author’s repo
- Also tested (in original paper) on Mars Rover Navigation, continuous control, and WebNav—though only GridWorld code is released here
Caveats
- TensorFlow 1.x era code; will likely need migration for TF 2.x
- 16×16 and 28×28 results are referenced in an issue, not shown in README directly
- Other domains from the paper (Mars Rover, WebNav) are not implemented in this repo
Verdict
Worth studying if you’re researching neural-symbolic hybrids or differentiable planning. Skip if you need production RL code—this is a faithful academic reproduction with the rough edges that implies.
Frequently asked
- What is hi-abhi/tensorflow-value-iteration-networks?
- A TensorFlow port of NIPS 2016's Best Paper, embedding value iteration directly inside a neural network for grid-world navigation.
- Is tensorflow-value-iteration-networks open source?
- Yes — hi-abhi/tensorflow-value-iteration-networks is open source, released under the Apache-2.0 license.
- What language is tensorflow-value-iteration-networks written in?
- hi-abhi/tensorflow-value-iteration-networks is primarily written in Python.
- How popular is tensorflow-value-iteration-networks?
- hi-abhi/tensorflow-value-iteration-networks has 549 stars on GitHub.
- Where can I find tensorflow-value-iteration-networks?
- hi-abhi/tensorflow-value-iteration-networks is on GitHub at https://github.com/hi-abhi/tensorflow-value-iteration-networks.