hhhuang/CAG
Why retrieve when you can preload? CAG bets on giant context windows
This repo implements Cache-Augmented Generation, a research alternative to RAG that replaces real-time retrieval with a giant preloaded context and a reusable KV cache.
Not currently ranked — collecting fresh signals.
star history
What it does
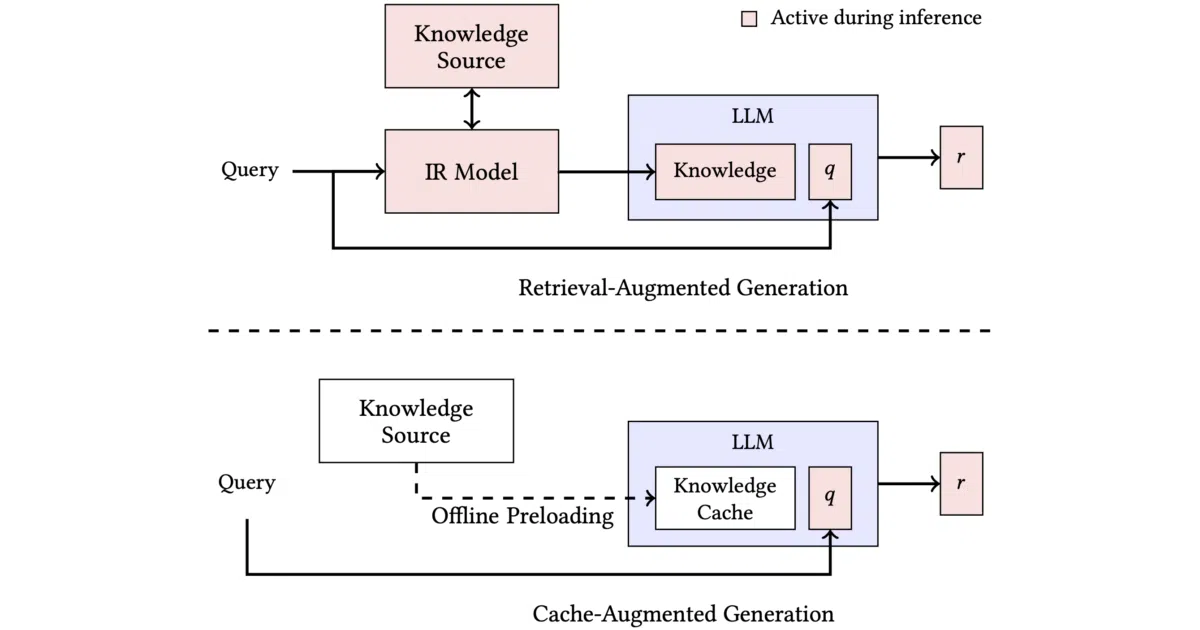
Cache-Augmented Generation (CAG) preloads all relevant documents into an LLM’s extended context window and saves the resulting KV cache, eliminating the need for a separate retrieval step during inference. The repo provides experimental scripts that compare this approach against traditional RAG on question-answering datasets. It accompanies a paper to be presented at the ACM Web Conference 2025.
The interesting bit
Instead of wrestling with vector databases and retrieval accuracy, CAG treats the context window as a brute-force knowledge store—trading architectural complexity for the assumption that your corpus fits in RAM and the model’s context limit. The authors argue this yields lower latency and fewer moving parts when the knowledge footprint is small enough.
Key highlights
- Bypasses real-time retrieval by preloading knowledge into the LLM context and caching the resulting KV state.
- Claims lower latency, fewer retrieval errors, and simpler architecture than RAG, with comparable or superior output quality.
- Evaluates on SQuAD and HotpotQA using BERTScore similarity against a built-in RAG baseline.
- Uses Llama-3.1-8B-Instruct as its primary example model.
Caveats
- Requires the entire knowledge source to fit within the LLM’s context window.
- Performance may degrade with very long contexts, per the authors’ cited reference.
- The codebase is a pair of experimental scripts (
rag.pyandkvcache.py), not a reusable framework.
Verdict
Worth exploring if you maintain a small, fixed knowledge base and want to trade retrieval infrastructure for context-window bloat. Not the answer for unbounded, dynamic, or massive-scale document collections.
Frequently asked
- What is hhhuang/CAG?
- This repo implements Cache-Augmented Generation, a research alternative to RAG that replaces real-time retrieval with a giant preloaded context and a reusable KV cache.
- Is CAG open source?
- Yes — hhhuang/CAG is open source, released under the MIT license.
- What language is CAG written in?
- hhhuang/CAG is primarily written in Python.
- How popular is CAG?
- hhhuang/CAG has 1.5k stars on GitHub.
- Where can I find CAG?
- hhhuang/CAG is on GitHub at https://github.com/hhhuang/CAG.