graykode/xlnet-Pytorch
XLNet dissected: one undergrad's readable PyTorch port
A stripped-down, single-file XLNet implementation that actually fits in your head — and your GPU.
Not currently ranked — collecting fresh signals.
star history
What it does
This is a minimal PyTorch re-implementation of XLNet, the permutation-based language model that beat BERT on GLUE back in 2019. It runs pre-training on a single text file with batch size 1, exposing every hyperparameter from reuse_len to mask_beta as CLI flags. A Jupyter notebook version runs on Colab for the GPU-poor.
The interesting bit
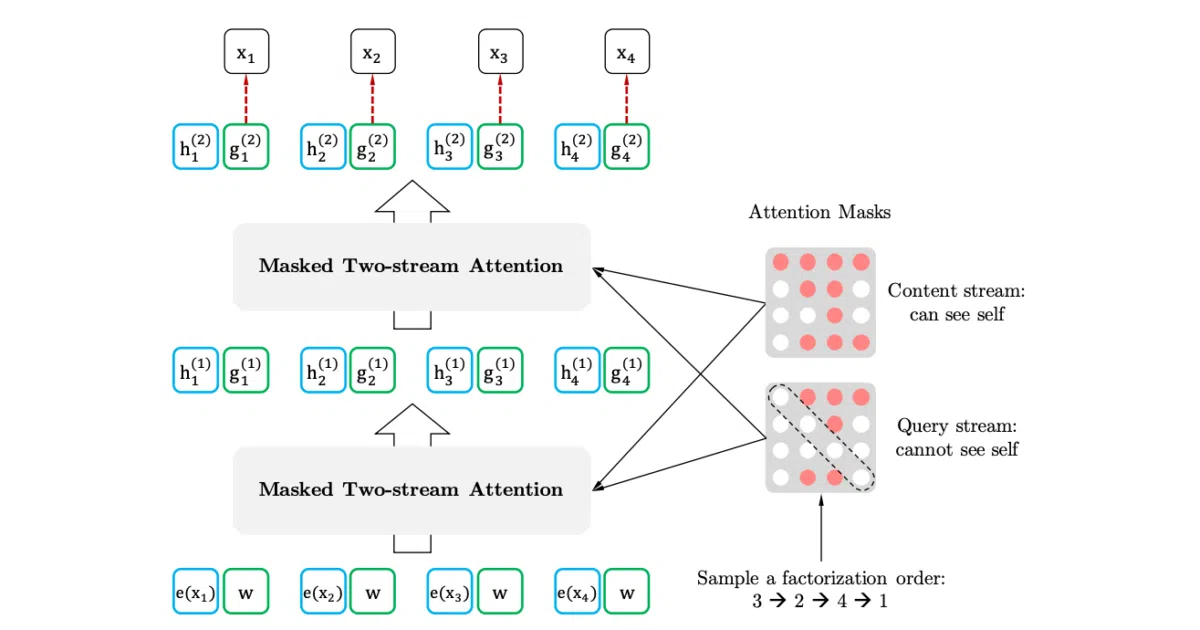
The original Google/CMU XLNet repo is industrial-scale TensorFlow. This is essentially a pedagogical autopsy: one undergraduate re-built the core architecture — permutation language modeling, two-stream attention, Transformer-XL memory caching — in plain PyTorch you can step through in an afternoon. The README even walks through the paper’s key diagrams one by one, which is rarer than it should be.
Key highlights
- Single-file pre-training script (
main.py) with ~dozen exposed hyperparameters matching the paper - Uses Hugging Face’s BERT tokenizer as a stopgap (SentencePiece migration “soon” per README)
- Includes paper’s hyperparameter table and GLUE benchmark comparison vs. BERT
- Colab notebook for zero-install experimentation
- Apache 2.0, same as upstream
Caveats
- “Simple” here means readable, not fast: batch size 1, no distributed training, no fine-tuning scripts visible
- Tokenizer is still BERT’s WordPiece, not XLNet’s original SentencePiece
- No training logs, checkpoints, or reproducibility notes provided
Verdict
Grab this if you’re trying to understand why XLNet’s permutation trick works and don’t want to fight a 10K-line TF codebase. Skip it if you need production pre-training or fine-tuning pipelines — this is a teaching skeleton, not a workhorse.
Frequently asked
- What is graykode/xlnet-Pytorch?
- A stripped-down, single-file XLNet implementation that actually fits in your head — and your GPU.
- Is xlnet-Pytorch open source?
- Yes — graykode/xlnet-Pytorch is open source, released under the Apache-2.0 license.
- What language is xlnet-Pytorch written in?
- graykode/xlnet-Pytorch is primarily written in Jupyter Notebook.
- How popular is xlnet-Pytorch?
- graykode/xlnet-Pytorch has 581 stars on GitHub.
- Where can I find xlnet-Pytorch?
- graykode/xlnet-Pytorch is on GitHub at https://github.com/graykode/xlnet-Pytorch.