google-research/scenic
A JAX Vision Toolkit That Embraces Copy-Paste Over Abstraction
Scenic is a Google Research JAX/Flax codebase for large-scale vision research that deliberately favors forking and copy-pasting over adding abstraction layers.
Not currently ranked — collecting fresh signals.
star history
What it does
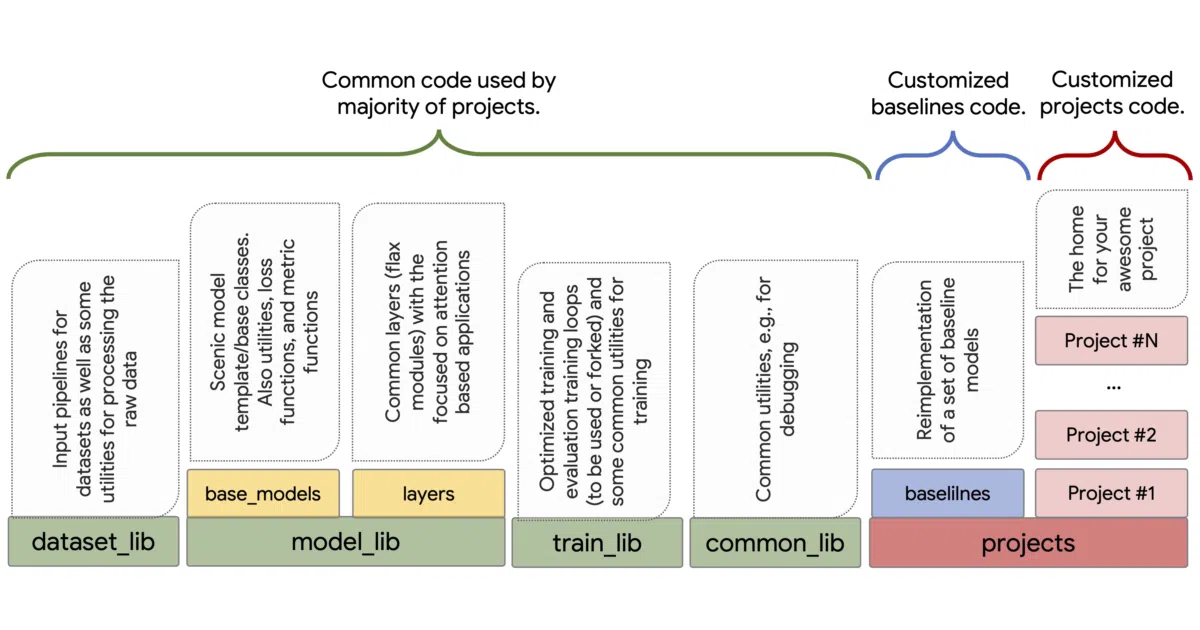
Scenic is a set of lightweight JAX/Flax libraries and fully fleshed-out research projects for training large-scale, attention-based computer vision models across images, video, audio, and multimodal tasks. It handles the boilerplate of multi-device, multi-host training—dataset pipelines, optimized loops, metrics, and bipartite matchers—while leaving the model-specific logic in standalone project directories. The result is something between a framework and a living research archive: you can run existing baselines like ViT, DETR, CLIP, or SAM, or fork them into custom experiments.
The interesting bit
Most frameworks try to abstract away repetition; Scenic’s stated philosophy is to prefer forking and copy-pasting over increasing abstraction, only upstreaming code to shared libraries once it has proven widely useful. That inversion keeps the library layer minimal and the project layer flexible, letting researchers customize anything from hyperparameters down to the training loop without fighting a rigid API.
Key highlights
- Hosts dozens of first-party research projects (ViViT, TokenLearner, PolyViT, Dream Fields, etc.) and reproduced baselines (ViT, DETR, CLIP, SAM, ResNet, U-Net)
- Library-level code covers scalable dataset I/O (
dataset_lib), attention-focused model layers and matchers (model_lib), and forkable trainers (train_lib) - Supports a wide spectrum of reuse, from config-only runs to fully custom architectures, losses, and evaluation loops
- Explicitly built for large-scale training across multiple hosts and accelerators
Caveats
- The README notes that specific projects and baselines may require extra dependencies beyond the core install
- It is tightly coupled to the JAX/Flax ecosystem, so PyTorch or TensorFlow users are out of luck
Verdict
Grab it if you are a JAX-based vision researcher who wants production-grade training infrastructure without the bloat of a monolithic framework; skip it if you need a unified PyTorch stack or a polished end-user API.
Frequently asked
- What is google-research/scenic?
- Scenic is a Google Research JAX/Flax codebase for large-scale vision research that deliberately favors forking and copy-pasting over adding abstraction layers.
- Is scenic open source?
- Yes — google-research/scenic is open source, released under the Apache-2.0 license.
- What language is scenic written in?
- google-research/scenic is primarily written in Python.
- How popular is scenic?
- google-research/scenic has 3.8k stars on GitHub.
- Where can I find scenic?
- google-research/scenic is on GitHub at https://github.com/google-research/scenic.