gokayfem/awesome-vlm-architectures
A field guide to vision-language model blueprints
Because comparing how popular VLMs bridge pixels and tokens shouldn't require fifty open arXiv tabs.
Not currently ranked — collecting fresh signals.
star history
What it does
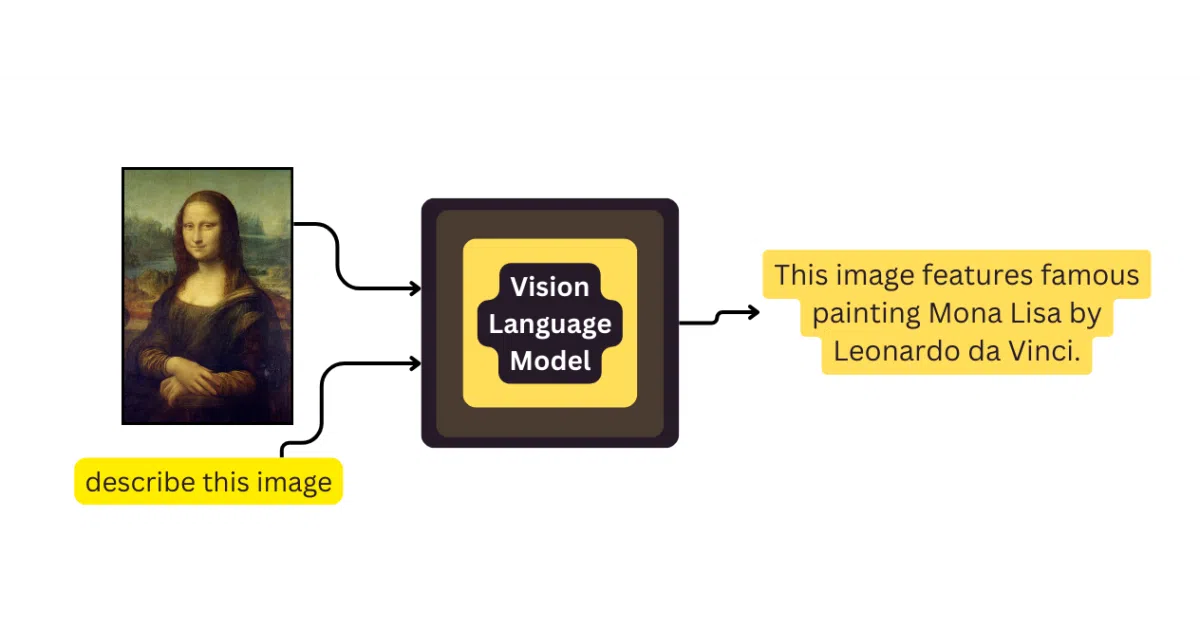
This repository is a curated index of vision-language models—LLaVA, CLIP, Qwen-VL, DeepSeek-VL2, and roughly seventy others. Each entry pairs an architecture diagram with collapsible notes on training procedures and datasets, letting you compare how different teams wired image encoders to language models without drowning in papers. It is essentially an Awesome List for VLM blueprints.
The interesting bit
Instead of treating papers as black boxes, the list surfaces the actual plumbing: linear projection layers, cross-attention fusion, mixture-of-experts routing, and encoder-free designs. That turns it into a pattern catalog for anyone trying to understand why their multimodal model works—or doesn’t.
Key highlights
- Covers 70+ models, from early CLIP and BLIP variants to recent releases like Janus-Pro, ARIA, and MiniCPM-o-2.6.
- Every entry includes a visual architecture diagram and expandable details on training stages and datasets.
- Also catalogs related tools such as DualView, a side-by-side output comparator for VLMs.
- Maintained in the standard Awesome List format with quick links to papers, code, and demos.
Caveats
- The README is a single long page; navigation depends on anchor links and browser search.
- Depth varies by entry, and the provided source truncates partway through the list, so some newer additions may be less fleshed out.
Verdict
Bookmark it if you are building, fine-tuning, or evaluating multimodal models and need a quick survey of alignment strategies. Skip it if you want a unified library or runnable training pipeline.
Frequently asked
- What is gokayfem/awesome-vlm-architectures?
- Because comparing how popular VLMs bridge pixels and tokens shouldn't require fifty open arXiv tabs.
- Is awesome-vlm-architectures open source?
- Yes — gokayfem/awesome-vlm-architectures is open source, released under the CC0-1.0 license.
- What language is awesome-vlm-architectures written in?
- gokayfem/awesome-vlm-architectures is primarily written in Markdown.
- How popular is awesome-vlm-architectures?
- gokayfem/awesome-vlm-architectures has 1.3k stars on GitHub.
- Where can I find awesome-vlm-architectures?
- gokayfem/awesome-vlm-architectures is on GitHub at https://github.com/gokayfem/awesome-vlm-architectures.