ga642381/speech-trident
A Field Guide to the Speech-AI Paper Deluge
It manually tracks the papers bridging speech representation, neural codecs, and language modeling so you don't have to drown in arXiv alerts.
Not currently ranked — collecting fresh signals.
star history
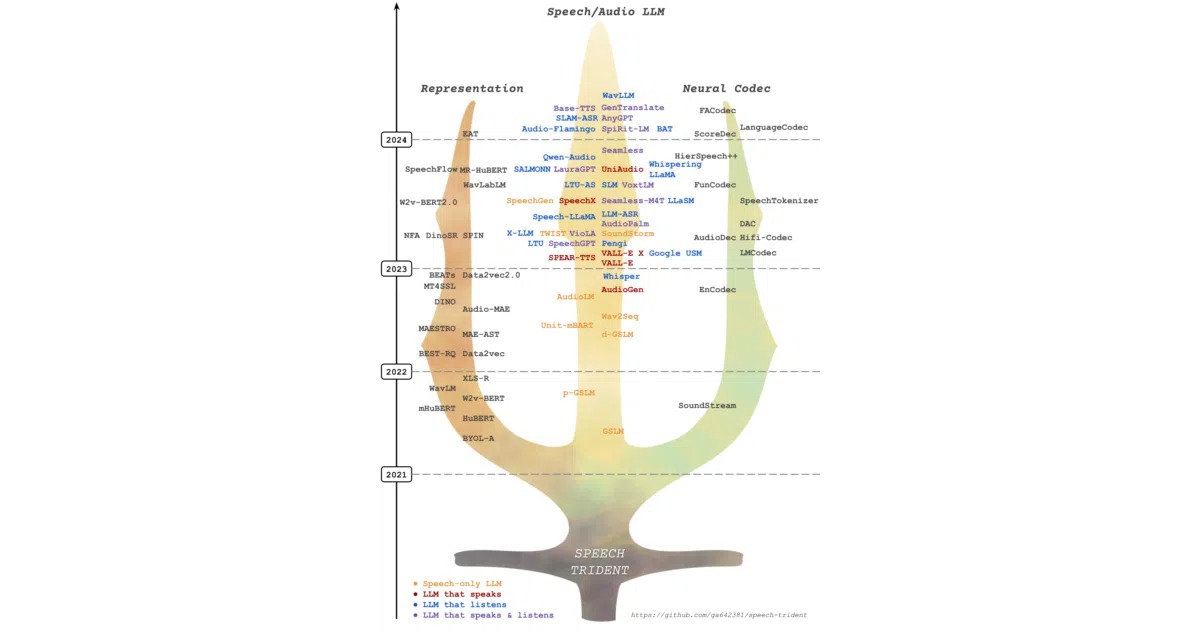
What it does Speech Trident is a curated survey and bibliography of the speech/audio large-language-model ecosystem. It organizes papers and models into three buckets: speech representation learning (semantic tokens), neural audio codecs (acoustic tokens), and end-to-end speech language models. The README functions as a living literature review with short topical summaries and direct links to arXiv, GitHub, and technical reports.
The interesting bit Instead of dumping every paper, the maintainers slice the field along the actual engineering stack—how speech gets compressed, represented, and then fed to an LLM. They also surface a companion 2025 survey paper and a 2026 spoken-dialogue spin-off, suggesting the curation is active and opinionated rather than merely exhaustive.
Key highlights
- Dense, chronologically sorted tables linking to papers and code for dozens of recent speech/audio LLMs, including GPT-4o, Moshi, and GLM-4-Voice.
- Explicitly splits the stack into semantic tokens, acoustic tokens, and LM heads—useful if you are deciding where to plug in your own model.
- Maintained by working speech researchers who also publish companion survey papers (2025 landscape survey, 2026 spoken-dialogue survey).
- Direct links to arXiv, GitHub repos, and technical reports with minimal editorial fluff.
Caveats
- It is a reading list, not a framework; there is no code to run and no benchmarks to compare.
- The README is a single long markdown file, so deep search or filtering is limited to your browser’s find function.
- Some entries are just paper titles and links with no annotation, so you still need to read the paper to judge relevance.
Verdict Researchers and engineers trying to get oriented in speech/audio LLMs without reading every abstract will save time here. If you are hunting for a drop-in library or pretrained weights to fine-tune today, look elsewhere.
Frequently asked
- What is ga642381/speech-trident?
- It manually tracks the papers bridging speech representation, neural codecs, and language modeling so you don't have to drown in arXiv alerts.
- Is speech-trident open source?
- Yes — ga642381/speech-trident is an open-source project tracked on heatdrop.
- How popular is speech-trident?
- ga642381/speech-trident has 1.2k stars on GitHub.
- Where can I find speech-trident?
- ga642381/speech-trident is on GitHub at https://github.com/ga642381/speech-trident.