fundamentalvision/Deformable-DETR
DETR, but it finishes training this week
Deformable DETR replaces DETR’s global image attention with sparse, learnable sampling points so end-to-end object detection converges in 50 epochs instead of 500.
Not currently ranked — collecting fresh signals.
star history
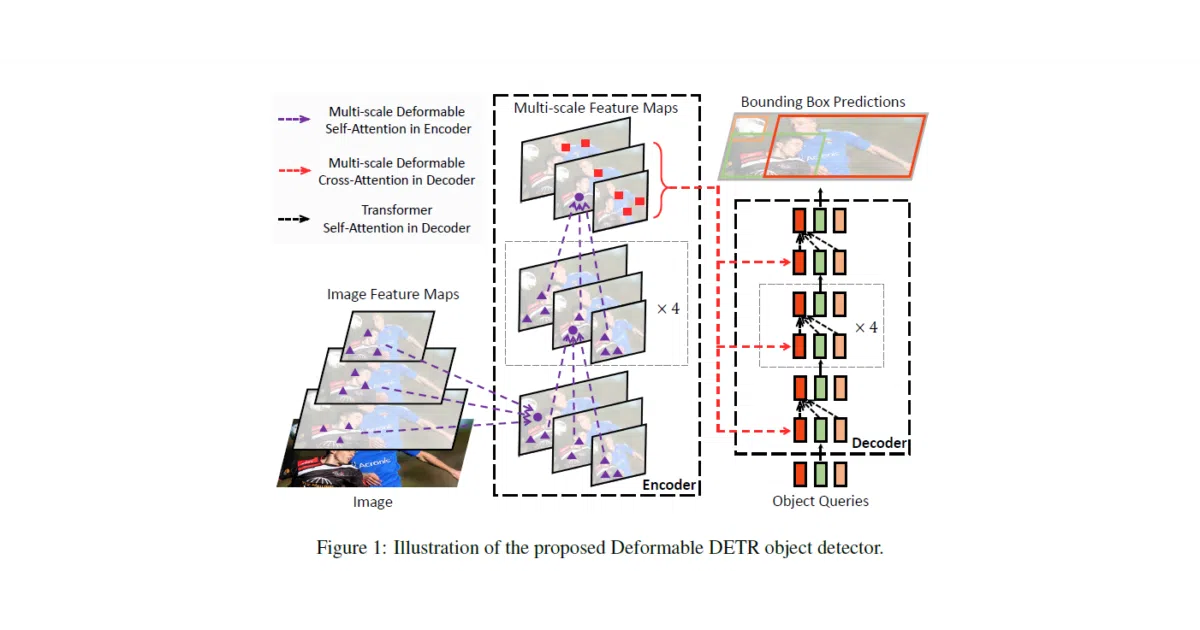
What it does Deformable DETR keeps DETR’s end-to-end simplicity—no hand-tuned anchors or NMS pipelines—while cutting training time from 500 epochs to 50. On COCO it beats baseline DETR on small-object AP (27.1 vs. 20.5) and the full multi-scale model exceeds overall accuracy (44.5 vs. 42.0), though it relies on compiled custom CUDA operators rather than pure PyTorch.
The interesting bit The transformer attention module doesn’t gaze at the whole feature map. It learns a handful of sampling offsets around a reference point and only attends to those locations, which is how it stays efficient on high-resolution images without sacrificing the global receptive field.
Key highlights
- 10× faster convergence than DETR: 50 epochs versus 500, with better COCO performance across the board.
- Deformable attention sparsely samples key points, reducing the quadratic complexity that chokes standard transformers on large feature maps.
- Optional iterative bounding-box refinement and a two-stage variant push AP up to 46.9.
- Distributed training support for single-node, multi-node, and Slurm setups out of the box.
- Requires custom CUDA extensions; not a pure-PyTorch drop-in.
Caveats
- The authors warn that this public release was ported from an internal codebase, so final accuracy and runtime differ slightly from the paper.
- Linux and a compatible CUDA toolchain are effectively mandatory because of the custom operators.
Verdict Worth a look if you want DETR’s clean architecture without the week-long training camp. Skip it if you are stuck on CPU-only hardware or need a dependency-light demo.
Frequently asked
- What is fundamentalvision/Deformable-DETR?
- Deformable DETR replaces DETR’s global image attention with sparse, learnable sampling points so end-to-end object detection converges in 50 epochs instead of 500.
- Is Deformable-DETR open source?
- Yes — fundamentalvision/Deformable-DETR is open source, released under the Apache-2.0 license.
- What language is Deformable-DETR written in?
- fundamentalvision/Deformable-DETR is primarily written in Python.
- How popular is Deformable-DETR?
- fundamentalvision/Deformable-DETR has 4k stars on GitHub.
- Where can I find Deformable-DETR?
- fundamentalvision/Deformable-DETR is on GitHub at https://github.com/fundamentalvision/Deformable-DETR.