frotms/PaddleOCR2Pytorch
Escaping PaddlePaddle for PyTorch, one OCR model at a time
A port of PaddleOCR's inference stack to PyTorch so you can run their trained models without installing PaddlePaddle.
Not currently ranked — collecting fresh signals.
star history
What it does
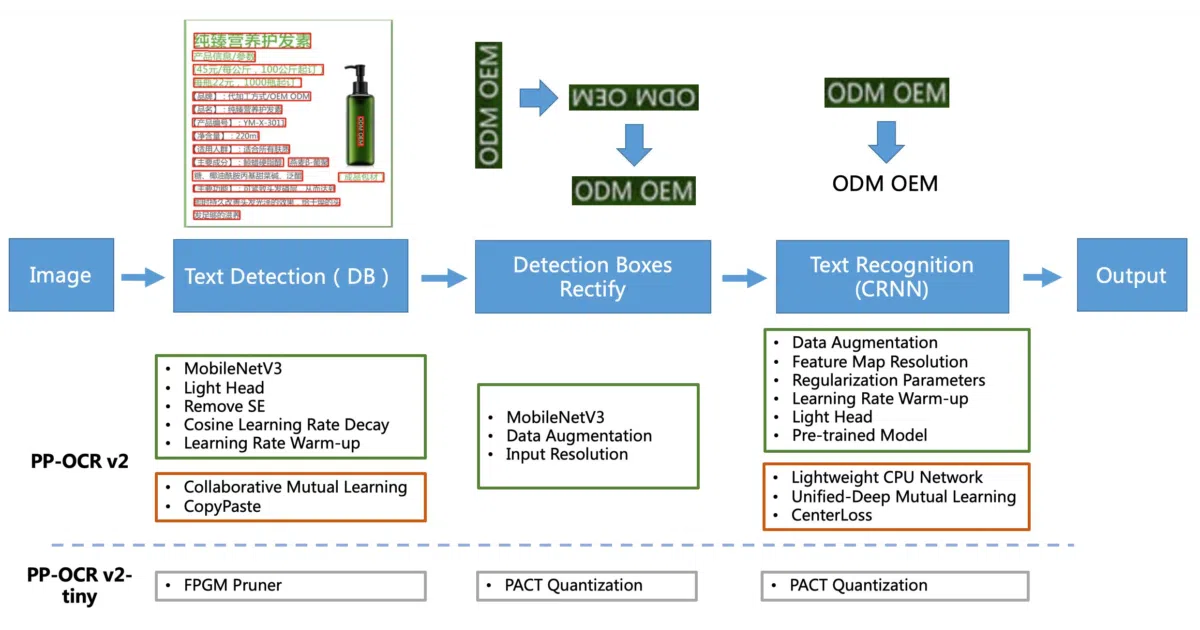
PaddleOCR2Pytorch converts Baidu’s PaddleOCR models—detection, direction classification, and text recognition—into PyTorch-compatible weights you can load and run. It covers the PP-OCR family (mobile and server variants), supports multilingual text including Chinese, Japanese, Korean, and European languages, and handles vertical text and long-form recognition. The project also serves as a reference implementation for anyone trying to translate Paddle dynamic-graph code to PyTorch.
The interesting bit
The README opens with the word “白嫖” (roughly: freeloading). The author’s candor matches the project’s purpose: letting you extract value from PaddleOCR’s heavily optimized models—some compressed down to 3.5MB—without committing to the PaddlePaddle ecosystem. It’s a bridge, not a rewrite.
Key highlights
- Pre-converted PyTorch weights available via Baidu Netdisk (extraction code: 6clx)
- Supports PP-OCRv2 through v5, including the latest v5 release with handwritten-text improvements
- Multilingual coverage: 27+ languages in the model zoo
- Includes formula recognition (CAN), text super-resolution (Text Telescope), and layout analysis pipelines
- Mobile-optimized variants for CPU inference
Caveats
- Model downloads require Baidu Netdisk, which is region-restricted and slow outside China
- The TODO list is extensive: PP-OCRv5’s document-orientation modules, PP-StructureV3 PDF parsing, and PP-ChatOCRv4 integration are all marked unfinished
- No training code; inference only
Verdict
Worth a look if you’re already invested in PyTorch and need battle-tested OCR models without ecosystem friction. Skip it if you need end-to-end training or live outside Baidu Netdisk’s effective service area.
Frequently asked
- What is frotms/PaddleOCR2Pytorch?
- A port of PaddleOCR's inference stack to PyTorch so you can run their trained models without installing PaddlePaddle.
- Is PaddleOCR2Pytorch open source?
- Yes — frotms/PaddleOCR2Pytorch is open source, released under the Apache-2.0 license.
- What language is PaddleOCR2Pytorch written in?
- frotms/PaddleOCR2Pytorch is primarily written in Python.
- How popular is PaddleOCR2Pytorch?
- frotms/PaddleOCR2Pytorch has 1.2k stars on GitHub.
- Where can I find PaddleOCR2Pytorch?
- frotms/PaddleOCR2Pytorch is on GitHub at https://github.com/frotms/PaddleOCR2Pytorch.