freedmand/semantra-python
Semantic search for your hard drive, minus cloud and hallucinations
Semantra exists to let you query local documents by meaning through a private web UI, without cloud uploads or generative AI fabrications.
Velocity · 7d
+0.0
★ / day
Trend
→steady
star history
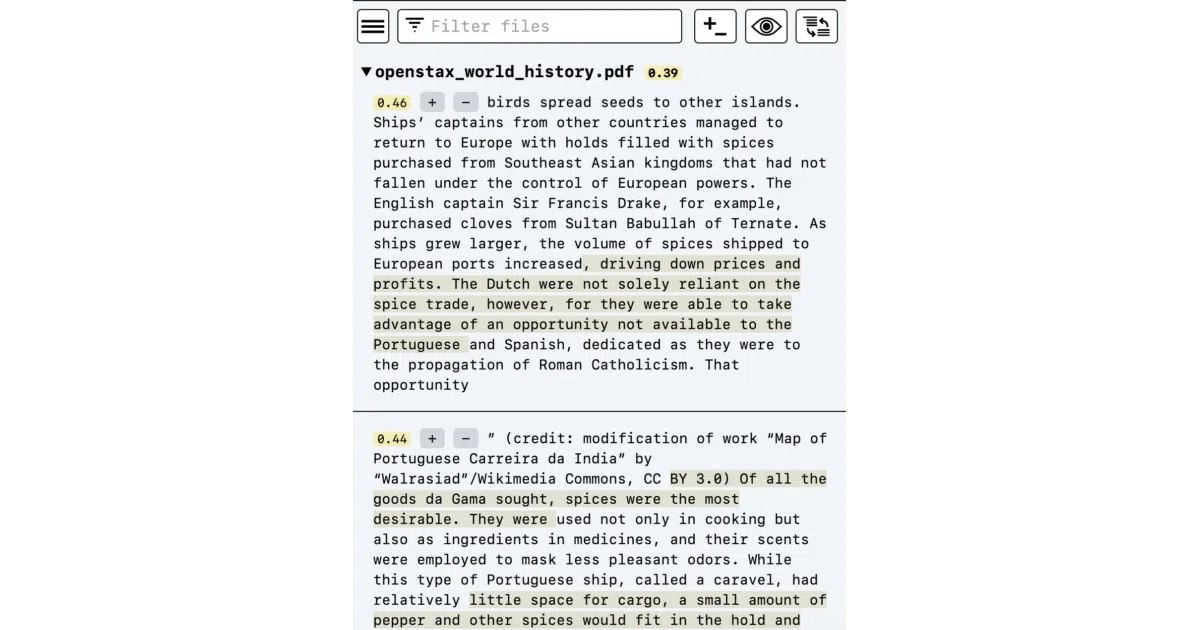
What it does Semantra is a command-line tool that ingests local text and PDF files, embeds their contents using a local machine-learning model (or OpenAI, if you prefer), and launches a local web interface for querying them by semantic meaning rather than exact keyword matches. You type a concept, and it surfaces relevant passages across your documents, scoring them from 0 to 1 and highlighting the most pertinent chunks directly in the source files. It is built for private, offline use: your documents stay on your machine, and the search index is built and stored locally.
The interesting bit The tool deliberately excludes generative AI like ChatGPT, treating primary source material as the only source of truth and leaving synthesis and verification to the human in the loop. More unusually, it supports query arithmetic—adding or subtracting terms with plus and minus signs in the search box, or tagging results as positive or negative filters—to sculpt precise semantic intent without writing boolean strings.
Key highlights
- Runs fully offline by default using local embedding models; OpenAI is optional.
- Supports semantic query arithmetic (
+and-modifiers) to refine search intent. - Highlights relevant passages inside documents and scores results from 0–1.00.
- Caches processed documents so subsequent launches are near-instantaneous.
- Configurable embedding models, windowing strategies, and approximate or exact nearest-neighbor search backends.
Caveats
- The project is explicitly described as being in early stages.
- Semantic search always returns results even for irrelevant queries—scores may simply be low—so users must judge relevance themselves.
- Exact substring matches are not guaranteed; the embedding model may miss a word if its contextual meaning differs from the query vector.
Verdict Journalists, researchers, and students drowning in primary sources should take a look; if you need generative summaries or cloud-native collaboration, this is intentionally not your tool.