facebookresearch/TensorComprehensions
Write math, get CUDA: a DSL that breeds fast kernels
Facebook Research's Tensor Comprehensions lets you describe ML operations in a terse notation, then autotunes them into near-peak GPU performance without hand-writing CUDA.
Not currently ranked — collecting fresh signals.
star history
What it does
Tensor Comprehensions is a C++ library with Python bindings that JIT-compiles high-performance ML kernels from a concise mathematical notation. You write something resembling Einstein summation—O(n, c1, c3, h, w) +=! I0(...) * I1(...)—and TC handles the rest: Halide for scheduling, ISL for polyhedral optimization, NVRTC or LLVM for code generation. It plugs into PyTorch and Caffe2, so the resulting kernel drops into familiar tensor code.
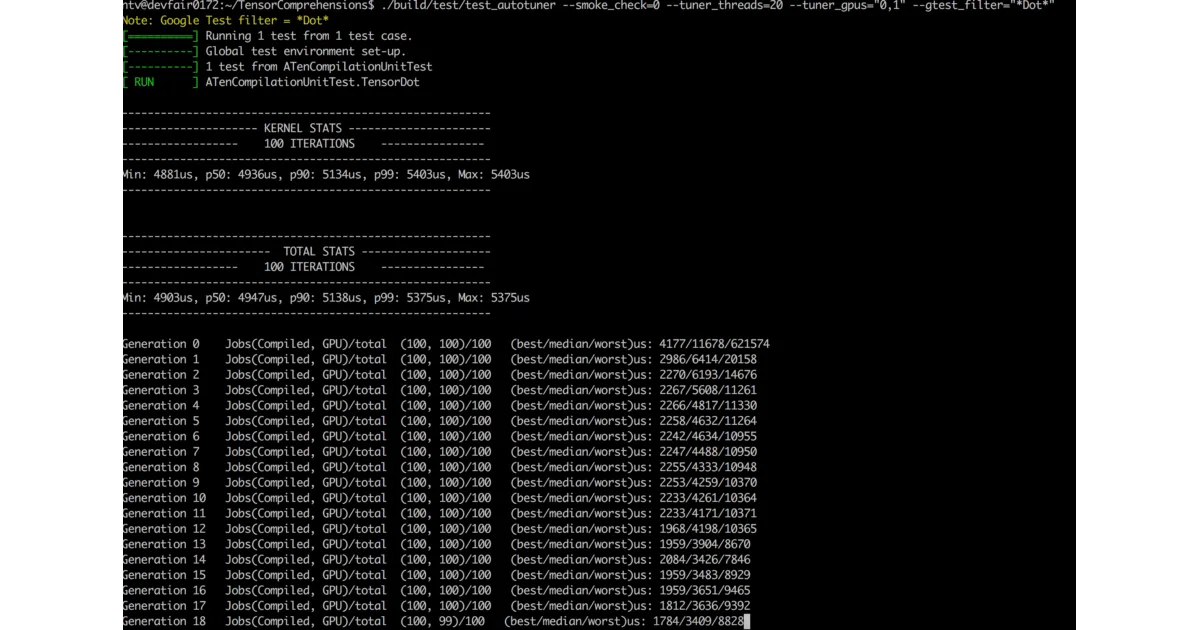
The interesting bit
The autotuner uses a genetic search that evolves mapping options across generations. The README shows a tensordot kernel going from 7,345μs (naive) to 220μs in two generations on a P100. Crucially, you autotune once per operation definition, then reuse those options across different tensor sizes—amortizing the ~28-second search cost.
Key highlights
- Mathematical syntax close to index notation; no explicit loops or thread blocks
- Genetic autotuner searches the schedule space automatically
- Targets CUDA via NVRTC or CPU via LLVM; framework-agnostic at core
- Claims 80%+ of peak shared memory bandwidth after autotuning on some kernels
- Apache 2.0, with conda binaries and Docker builds available
Caveats
- Register-level optimizations are “still in the work”; peak compute is not guaranteed
- The project appears dormant—last significant activity years ago, and it targets pre-Ampere GPU architectures
- Caffe2 integration is a historical curiosity at this point
Verdict
Worth studying if you build ML compilers or need to understand Halide-style scheduling. For production PyTorch work, look at torch.compile, Triton, or CUDA graphs instead—this is more research artifact than living toolchain.
Frequently asked
- What is facebookresearch/TensorComprehensions?
- Facebook Research's Tensor Comprehensions lets you describe ML operations in a terse notation, then autotunes them into near-peak GPU performance without hand-writing CUDA.
- Is TensorComprehensions open source?
- Yes — facebookresearch/TensorComprehensions is open source, released under the Apache-2.0 license.
- What language is TensorComprehensions written in?
- facebookresearch/TensorComprehensions is primarily written in C++.
- How popular is TensorComprehensions?
- facebookresearch/TensorComprehensions has 1.8k stars on GitHub.
- Where can I find TensorComprehensions?
- facebookresearch/TensorComprehensions is on GitHub at https://github.com/facebookresearch/TensorComprehensions.