facebookresearch/InferSent
Sentence embeddings from a dead-simple idea: train on entailment
Facebook Research's 2017 encoder that proved natural language inference data beats unsupervised methods for sentence representations.
Not currently ranked — collecting fresh signals.
star history
What it does
InferSent turns English sentences into 4096-dimensional vectors using a pre-trained BiLSTM encoder. You download a pickle, point it at GloVe or fastText vectors, and call encode(). The README claims ~1000 sentences per second on a single GPU with batch size 128.
The interesting bit The trick is the training objective: natural language inference (entailment, contradiction, neutral) rather than raw language modeling. The authors showed this supervised signal transfers better than SkipThought to classification, similarity, and entailment benchmarks — a result that looks obvious now but wasn’t then.
Key highlights
- Two model versions: V1 (GloVe + PTB tokenization) and V2 (fastText + Moses tokenization, no zero-padding in max-pooling)
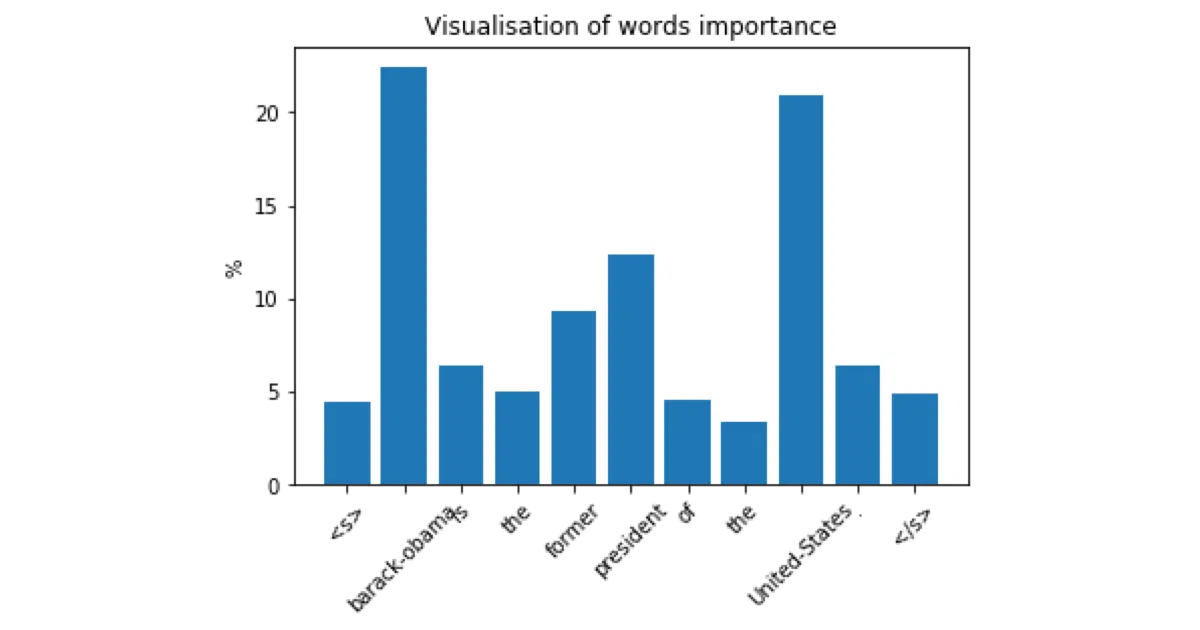
- Includes a
visualize()function to inspect per-word importance in sentence encodings - Evaluation table against SkipThought and fastText-BoV on 11 standard transfer tasks
- Ships with a
demo.ipynbfor quick start
Caveats
- Maintenance mode: the author removed
train_nli.pyand explicitly states no time to maintain beyond “simple scripts to get sentence embeddings” - Python 2/3 compatibility noted, but PyTorch version requirements are vague (“recent version”)
- Tokenization mismatch between V1/V2 is a footgun — the README warns you must match training tokenization for fair evaluation
Verdict Grab this if you need a battle-tested baseline for English sentence embeddings without fighting transformers. Skip it if you want multilingual support, active maintenance, or state-of-the-art results — the field has moved to sentence-transformers and larger pre-trained models.
Frequently asked
- What is facebookresearch/InferSent?
- Facebook Research's 2017 encoder that proved natural language inference data beats unsupervised methods for sentence representations.
- Is InferSent open source?
- Yes — facebookresearch/InferSent is an open-source project tracked on heatdrop.
- What language is InferSent written in?
- facebookresearch/InferSent is primarily written in Jupyter Notebook.
- How popular is InferSent?
- facebookresearch/InferSent has 2.3k stars on GitHub.
- Where can I find InferSent?
- facebookresearch/InferSent is on GitHub at https://github.com/facebookresearch/InferSent.