explosion/sense2vec
Word2vec with a part-of-speech filter
sense2vec disambiguates "duck" the verb from "duck" the noun by baking context into the vector key itself.
Not currently ranked — collecting fresh signals.
star history
What it does
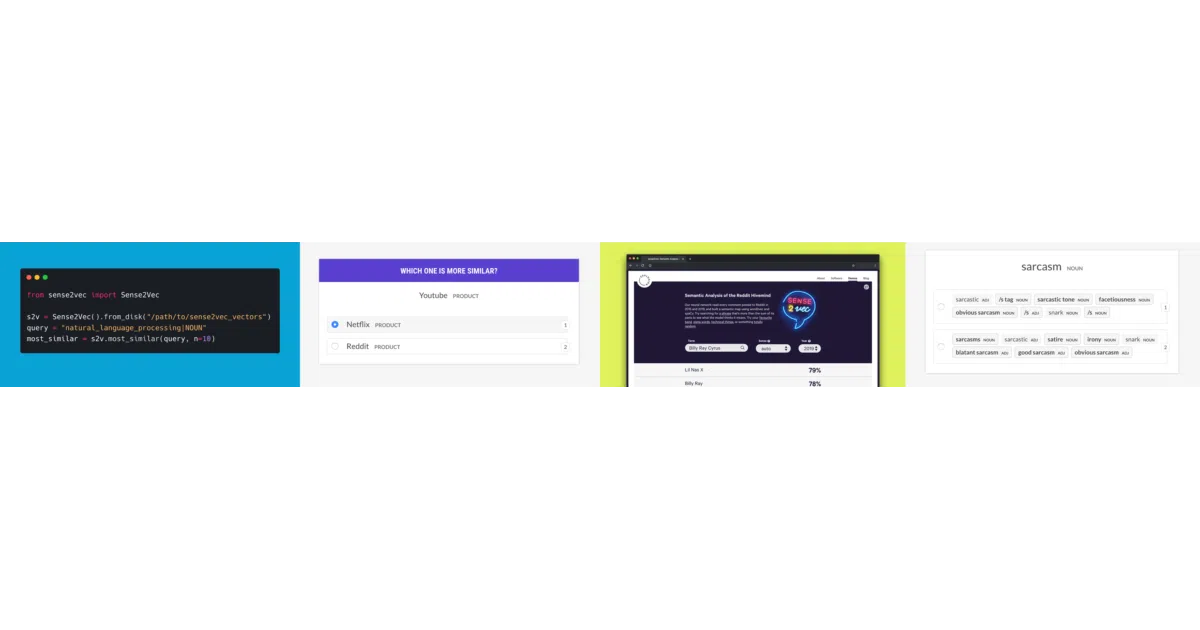
sense2vec trains word vectors where each key is a phrase plus a linguistic sense — like natural_language_processing|NOUN or Facebook|ORG. You can query similar phrases, check frequencies, or plug it into a spaCy pipeline so tokens and spans grow ._.s2v_vec and ._.s2v_most_similar() attributes. It ships with pretrained Reddit comment vectors (2015 and 2019) and can train new ones from raw text using fastText or GloVe under the hood.
The interesting bit The “sense” is just the part-of-speech tag or named-entity label, so the model learns separate embeddings for a word’s different grammatical jobs without any fancy disambiguation network. It’s a 2015 paper by Trask et al. that Explosion dusted off, reimplemented, and wired directly into spaCy v3 as a serializable pipeline component.
Key highlights
- Standalone class or spaCy
nlp.add_pipe("sense2vec")— your call. - Extension attributes on
TokenandSpanobjects for vector, frequency, and nearest-neighbor lookup. - Optional nearest-neighbor caching for faster “most similar” queries.
- Train your own vectors with a pretrained spaCy model + raw text + fastText/GloVe.
- Prodigy recipes for bootstrapping similar-phrase lists and NER match patterns.
- Pretrained Reddit vectors attached to GitHub releases; 2019 set is a 4 GB multi-part download.
Caveats
- The vector table is case-sensitive and keys must use underscores for spaces (
machine_learning|NOUN, notmachine learning|NOUN). - Span attributes default to the root’s POS tag if no entity label is present, and arbitrary slices may not have keys in the model.
- spaCy v2 users need the legacy
v1.xbranch andsense2vec==1.0.3.
Verdict Grab this if you want phrase-level semantic similarity that respects part-of-speech and entity type, especially inside an existing spaCy pipeline. Skip it if you need cross-lingual vectors or modern transformer-scale embeddings — this is classic shallow word2vec with a clever indexing trick.
Frequently asked
- What is explosion/sense2vec?
- sense2vec disambiguates "duck" the verb from "duck" the noun by baking context into the vector key itself.
- Is sense2vec open source?
- Yes — explosion/sense2vec is open source, released under the MIT license.
- What language is sense2vec written in?
- explosion/sense2vec is primarily written in Python.
- How popular is sense2vec?
- explosion/sense2vec has 1.7k stars on GitHub.
- Where can I find sense2vec?
- explosion/sense2vec is on GitHub at https://github.com/explosion/sense2vec.